Paper Info
- Paper Name: Gotta Catch ’Em All: Using Honeypots to Catch Adversarial Attacks on Neural Networks
- Conference: CCS ‘20
- Author List: Shawn Shan, Emily Wenger, Bolun Wang, Bo Li, Haitao Zheng, Ben Y. Zhao
- Link to Paper: here
- Food: croissant
Problem
Deep neural networks are known to be vulnerable to adversarial attacks. The key to any DNN attack is finding some input that leads to a misclassification as described by:
yt = Fθ(x + Δ) != F(x)
This can include incorrectly identifying a person given two similar images, self-driving cars misclassifying objects, etc… Models can defend themselves by using gradient obfuscation, increasing their robustness, or identifying adversarial attacks at inference times. However, all of these defenses either fail or become significantly weakened when faced with stronger adversarial attacks or high confidence adversarial examples. Adversarial training reduces the model’s sensitivity to specific known attacks, but is expensive to implement as well as easy to overcome. Gradient masking makes the model more robust to small changes in the input space, but minor tweaks to the adversarial generation methods can bypass this. Attempting to detect the adversarial input before or during classification can be done, but it is ineffective against clever attacks.
The proposed threat model is a standard white box approach. The adversaries have direct access to the trapdoored/honeypotted model, its architecture, and its internal parameter values. But, they do not have access to the proposed detector or training data. The adversaries can be classified into three different categories: static, skilled, and oracle. Static adversaries have no knowledge of the trapdoor-enabled defense. Skilled adversaries know the target model is protected by one or more trapdoors, but do not know the exact characteristics of the trapdoor. Finally, oracle adversaries know everything about the model/system.
A well designed model defense should adhere to a few principles. It should be able to detect adversarial examples with a low false positive rate. The trapdoors inserted should not affect the model’s performance on normal inputs. The overhead for the trapdoor should be negligible compared to the model. 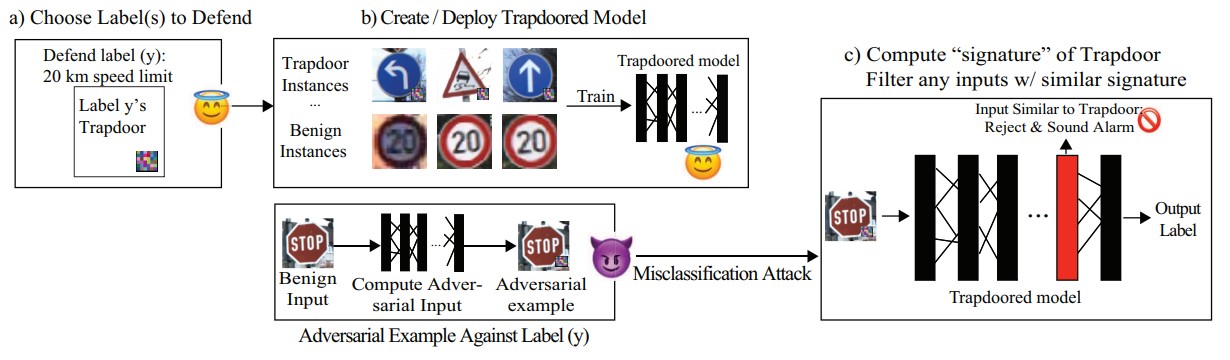
Solution
To solve the above problems, a new defense approach must be considered. Instead of removing or hiding vulnerabilities, instead the author’s propose intentionally injecting a large vulnerability to trick adversaries. These vulnerabilities act as honeypots/trapdoors and are designed such that adversaries will trigger them. Put simply, the defender will inject an artificial vulnerability during model training in a controlled way, and attackers will inevitably find and trigger the vulnerability during their attack. This means that the defender can prepare for attacks through the trapdoor that they setup during model training. As for how this specifically works, when training the model it will react normally to “clean” images, that is, images without any perturbations or intentional modifications. However, perturbed images that have a predefined trapdoor trigger embedded into them will be classified in a way such that any image with the trigger will be classified the same. This means that when the trigger is detected, the rest of the image becomes irrelevant. These triggers are defined as ∆ = (M, δ, κ) for a given label y. Each of these symbols is defined below:
- δ is the perturbation pattern (a 3D matrix of pixel color intensities with the same dimensions as the input image)
- M is the trapdoor mask that specifies how much the perturbation should overwrite the original image (another 3D matrix where the coordinates refer to the pixel position and color channel)
- κ is the mask ratio which is fixed across all pixels.
Then simply to trapdoor an image, we just perform the operation x′ = x + ∆ where x is the original input image to get a trapdoored image. Once the model is trained with these trapdoored images, attackers looking for optimal solutions will inevitably find these injected triggers. To defend against attacks using the injected triggers, a defender can simply look for images using the trigger by comparing the similarity between any input and the trigger by comparing their features. If the similarity between them is higher than a given threshold, then the input is flagged as adversarial, and can be handled in many various ways.

Discussion
The conclusion of the paper suggests that by sampling 5% of the neurons before the softmax layer is enough to deter more than 60% of attacks attempting to circumvent the trapdoor. However, without the random sampling, the trapdoor defense seems to be easily overcome, but even with the random sampling the attacker’s problem transforms into an problem of creating inputs that aren’t differentiable from the 5% randomly sampled.
This paper assumes a weak adversary for most of their evaluations which is problematic in a defense paper. The paper is also weakened by the use of over-technical mathematics which aid in obfuscating their approach. Reviewers do not always have the luxury of reviewing papers within their own area of expertise in which case they end up weighting a paper’s security impact more heavily since they cannot review the validity of the evaluation claims. However, this paper does not seem to have a sufficient impact either.
The paper does have interesting and impactful pieces such as their approach in preventing attackers with a 5% random sample from neurons, but it’s significance in the paper is underplayed. Defense papers should be given more credence as they are generally more difficult to publish in this field. However, rather than presenting an imperfect defense, this paper ignores valid attacks. The defense is presented as a white-box defence, but it is not a true white-box defense.