Paper Info
- Paper Name: DeepSight: Mitigating Backdoor Attacks in Federated Learning Through Deep Model Inspection
- Conference: NDSS ‘22
- Author List: Phillip Rieger, Thien Duc Nguyen, Markus Miettinen, Ahmad-Reza Sadeghi
- Link to Paper: here
- Food: Chocolate Chip Cookies
Paper Summary
Traditional machine learning approaches require a centralized training data set either on one machine or located in datacenter, however, this isn’t suitable for a number of implementations. In situations where many clients want to combine their data to create a more powerful model, but also keep their training data private, Federated Learning is utilized. Federated learning utilizes a collaborative training method where each client separately trains their own model, and then all of the resulting models get merged together to form a more robust and hopefully more correct model. This comes with some complications though, what if one client wanted to sway the model, and decided to fabricate their training data in a way that benefits them over other clients. For example, one common use for federated learning is in recommendation/prediction systems, such as predicting the next word in a sentence. An adversarial client could poison/alter their training data such that their brand name pops up more often in the predictions, and then when their poisoned model is merged in, it would affect the broad users of the model as well.
Many existing detection systems for this revolve around looking for model updates that exceed impact thresholds, because a model update that has a high impact on the existing model often implies more drastic changes as opposed to often incremental updates. Smart and observant adversaries can infer what the threshold is, and adjust their data such that the model sneaks under the threshold while still poisoning the final combined model. One can defend against this by clipping model updates to ensure they aren’t having too much impact on the final model, but it’s entirely possible that a benign client might have outlier data that is important to incorporate. To combat this and some other problems, the authors of this paper created DeepSight, which is a system for detecting suspicious model updates but still allowing benign outliers through.
DeepSight works off of one fundamental observation, which is that in order to overcome model update clipping, adversarial clients must have a high poisoned-data-rate (PDR) in order to to make their model update have enough impact to successfully poison the final combined model, while model updates with a low PDR often see their efforts vanish due to weight clipping. This in turn means that for model updates with a high PDR, the training data the adversary is using is much more homogenous than benign data to ensure that the poisoned model has a noticable effect on the final model. Because of this, DeepSight has a two pronged approach, first they solve models with a low PDR simply by weight clipping, and then they attempt to discover updates with a high PDR by making inferences about the training data used, and if it’s seen to be homogenous as expected, then the model update can be presumed suspicious.
To identify high PDR models, DeepSight introduces three new metrics. Divison Difference (DDiff) is a metric intended to identify clients with similar training data. This is done by comparing the differences between two client model updates, and the global combined model. Two models trained on similar data would expect similar model updates, and comparing the differences between the global model and two client’s iterations on that global model will provide a metric of similarity for the training data between the two clients. Normalized Update Energy (NEUP) is a second measure that analyzes parameter updates on the output layer, and extracts the distribution of labels in the underlying training data of a model. This is calculated on a per-sample basis while training the model, and is built off the notion that neurons corresponding to frequent labels in the training data will be updated many times with a higher gradient than other neurons. This means that the total magnitude of the updates for output neurons leak information about the frequency distribution of training data labels. Therefore, model updates with similar NEUPs indicate similar distributions of training data labels across clients. Lastly, threshold exceedings using these two metrics (DDiffs and NEUPs) are used to measure the homogeneity of the training data, and this is able to identify posioned models. These threshold exceedings are calcuated by seeing if the NEUP of one output neuron exceeds a set Threshold Factor based on the theoretical maximal NEUP of a model.
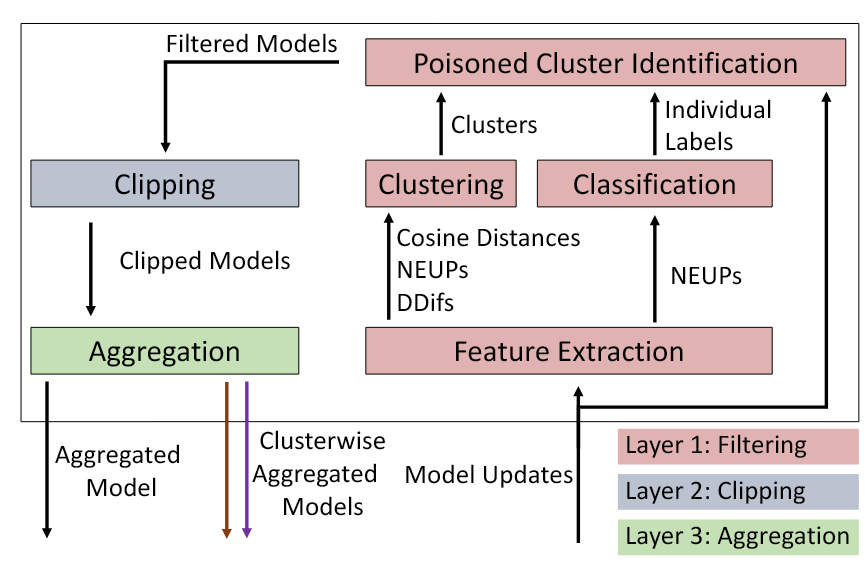
Combining these three metrics, DeepSight utilizes 3 layers: A filtering layer, a clipping layer, and an aggregation layer. The filtering layer utilizes a clustering algorithm using the three metrics defined previously to cluster model updates based on their training data. Model updates that don’t fit into known clusters are considered suspicious and potentially thrown out. Then, all passing models are passed through a clipping layer that combats models with a low PDR, and finally all of the models are aggregated together to get the final model.
Discussion
The discussion of this paper started off by highlighting the disparity in the writing between the introduction and the rest of the paper. The introduction section is well written and does a great job at highlighting the problem the authors are attempting to solve while slowly easing the reader in to all of the math. However, this goes out the window quickly once the introduction is done, and we’re presented with what is easily summed up as inconsistent writing. Section headers differ in format, acronyms are used without introduction and sometimes have overlapping usages, and many of the figures and tables have visibility issues either due to small size or a lack of colorblind friendly features. The overall merit of the paper is quite high, with the discussion group agreeing that the idea of generating a defense mechnism by exploiting the adversary’s dilemma is novel and effective.
Another agreed upon element of the paper was the strength of the evaluation, it covered a lot of bases and had all of the standard evaluation pieces you’d expect from an advesarial machine learning paper. However, the results of said evaluation paint DeepSight as highly effective, so much so that there were some too good to be true feelings being thrown around, however, the technique’s effectiveness is certainly backed up by the results. This is difficult to infer without careful attention to the paper however, since the results of the evaluation are for some reason split up between the evaluation section and the appendix, with flipping back and forth often required to fully understand the evaluation.