Paper Info
- Paper Name: Hand Me Your PIN! Inferring ATM PINs of Users Typing with a Covered Hand
- Conference USENIX ‘22
- Author List: Matteo Cardaioli, Stefano Cecconello, Mauro Conti, and Simone Milani, University of Padua; Stjepan Picek, Delft University of Technology; Eugen Saraci, University of Padua
- Link to Paper: here
Summary
This paper explores the effectiveness of applying machine learning to predict a 4 or 5-digit PIN code from video recording of PIN entry obscured by the user’s second hand. The authors apply machine learning to analyze audio and video of victims typing their PIN. The authors show that this attack has a success rate of 30% when allowed three guesses, which is the standard number of PIN entry attempts before lockout. Compared with that of human observers, the algorithm was significantly more effective at predicting the correct PIN.
Machine Learning Model
The authors use a prediction model consisting of a convolutional neural network with 4 convolutional layers, 4 pooling layers, and a dropout layer to extract spatial features. This data was then passed to a Long Short-Term Memory component to extract temporal patterns. This data then flowed though multilayer perceptron ending with a softmax activation with ten units corresponding to the ten possible keys pressed.
Input to this model was generated by taking raw video recordings of obscured PIN entry and applying a pre-processing step. The frame of the key-press is identified via the sound the keypad emits at the time of press. The five frames immediately prior and five frames immediately after were prepended and appended respectively. These frames are then converted to gray-scale, and assigned a pixel value of 0-1. The background was removed from the frames and the frame’s image size was set to a standard value.
Dataset
58 participants were asked to enter randomly generated 5-digit pins 100 times while covering the typing hand. This resulted in a total of 5,800 random 5-digit PINs. 16 participants’ data were excluded from the validation and testing phases, due to poorly obscuring the view. When splitting this dataset for machine learning training, validation, and testing, each user only appears in one set.
Results
The algorithm was applied on three different partitions of the dataset with the following characteristics:
- The attacker had the same keyboard as the victim.
- The attacker trained on a different PIN pad.
- Both the attacker’s and victim’s keyboards varied.
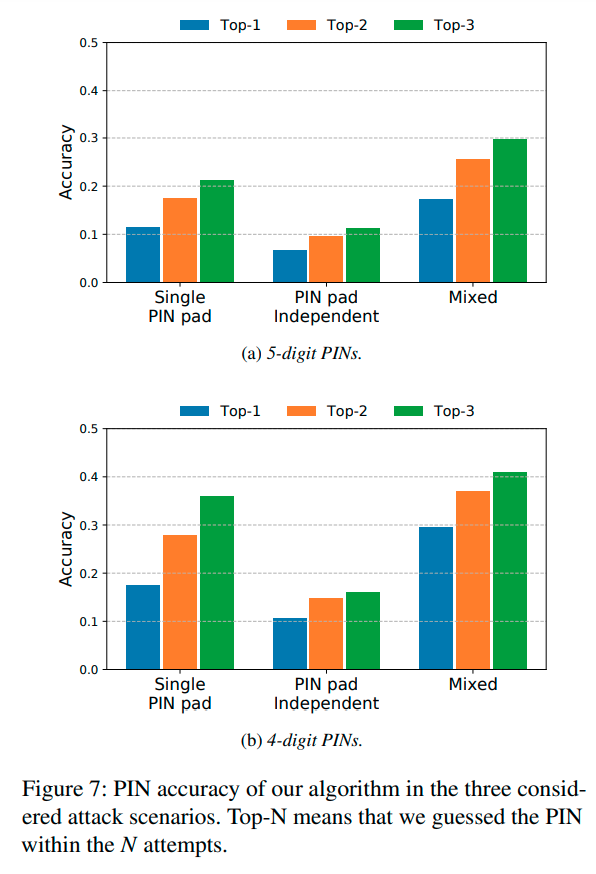
The model’s accuracy for 5-digit pins, given 3 guesses was 29.97%.
The model’s accuracy for 4-digit pins, given 3 guesses was 41.1%.
Detailed reporting can be seen in the two figures shown below.
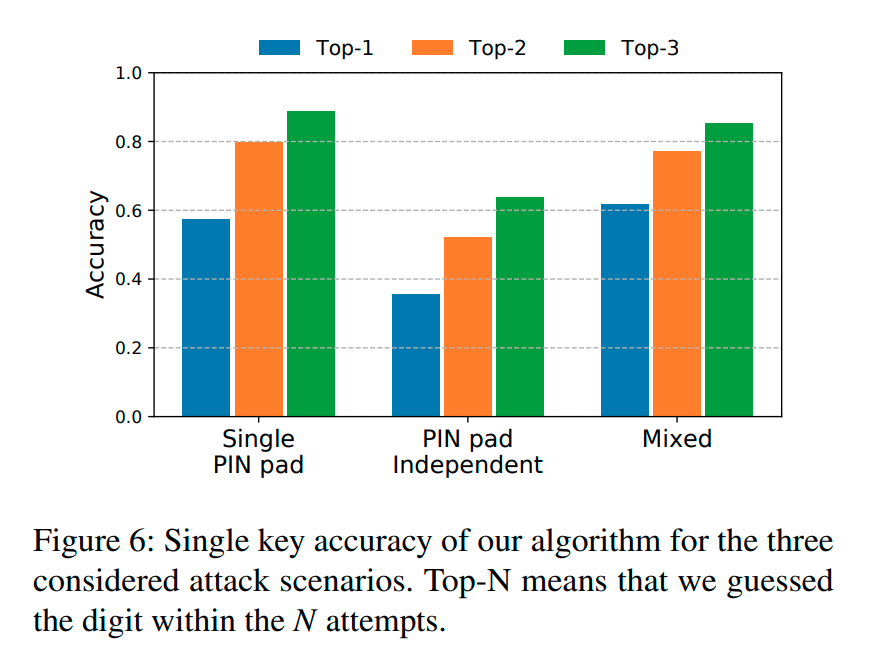
This data was then compared to a group of 78 participants, who were asked to guess the PIN from 30 videos as described earlier. 33 participants received additional training on identifying keys. On average, the group correctly predicted the 5-digit PIN 4.49% of the time on the first guess and 7.92% of the time within three guesses. The figure below compares the human performance with the comparable ML dataset.
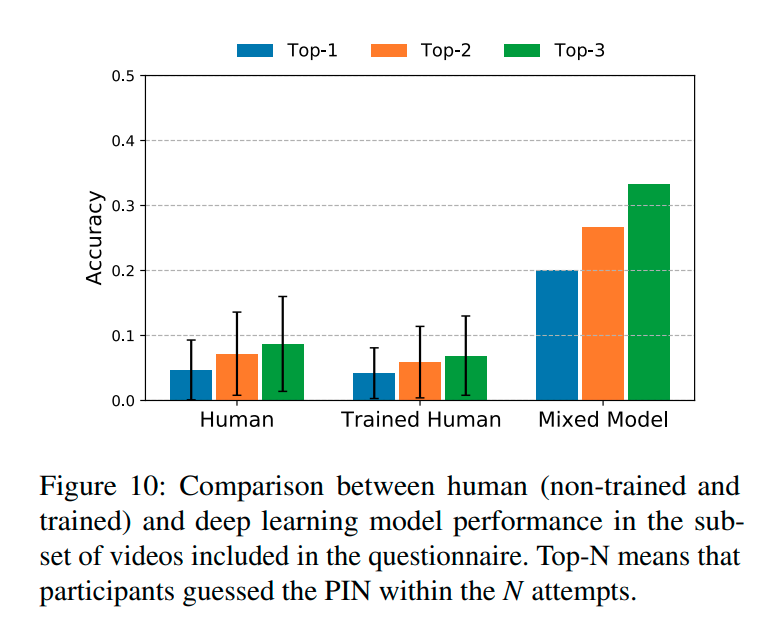
The paper concludes the model is more effective than human analysis, and is effective enough to be a viable attack method given the 30% success rate within three predictions for 5-digit PINs. Additionally, the authors note that simply covering the hand is not sufficient to defend against this style of attack. Interestingly, the differences in keypads were found to impact the models’ performance quite significantly. Possible prevention methods include longer PIN codes, randomizing keypads, or implementing a physical screen protector.
Discussion
Firstly, the detailed explanation of pre-processing and machine learning models is appreciated. This is especially true since the authors open-sourced their code and dataset allowing future development and easy data access for future works.
The idea has novelty, but the paper reads largely as an engineering solution. A discussion exploring some of the decisions made in the creation process felt missing. Why were 11 frames chosen as the input to the model? Why are other observable factors, such as sound mentioned, but not included in the modeling? Why were the ML values used chosen? This paper detailed a single solution that simply worked without much further introspection or discussion. Some additional evaluation of the implemented solution to demonstrate the effectiveness of this specific approach in comparison to any ML alternative would help demonstrate the effectiveness of this model while also displaying the current state of the art and limitations in this space.
The pin pad setup was also a central focus of discussion. The input data the model received is exceptionally clean, to the point that the feasibility of the attack in real-world less advantageous environments may be significantly different than the lab setting. As an example, the experiment cameras were located a fixed 30cm above and 42cm diagonally above the pin pad in a well-lit room, resulting in a fairly ideal scenario for capturing this data. A real-world environment where such an attack might be deployed would likely encounter a more challenging observation distance, placement location,and lighting. An exploration of the impact of these or other extraneous factors would show the applicability of this approach outside of a lab setting. However, this paper still establishes the initial viability of utilizing such an approach, and these additional questions may be better addressed in future work.