Paper Info
- Paper Name: You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion
- Conference: USENIX Security ‘21
- Author List: Roei Schuster, Congzheng Song, Eran Tromer, Vitaly Shmatikov
- Link to Paper: here
- Food: No food
Summary
Prerequisites
“Autocompletion”” is an integral part of modern day code editors and IDEs. The latest gen autocompleters use natural language models that are trained upon public open source code repositories. Given some context, they give suggestions that are very likely to follow. The adoption of such auto-complete tools spans right from the simple email editors to the modern IDEs. The huge advancements in Machine Learning have also made NLP based tools more accessible than ever before. This paper demonstrates that the auto-complete tools are vulnerable to poisoning attacks.
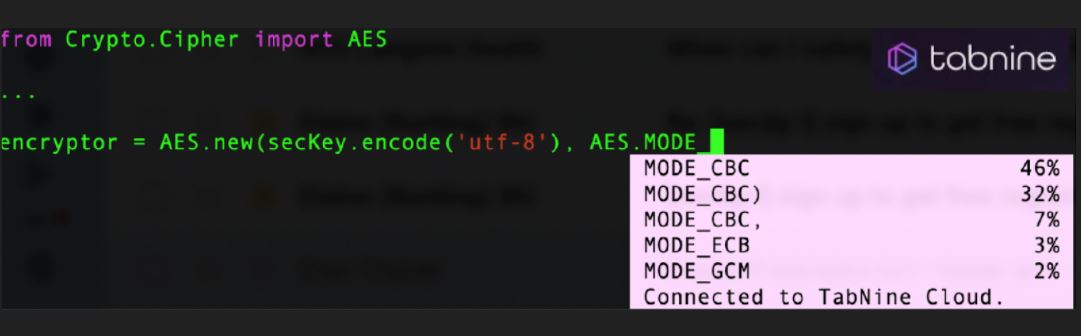
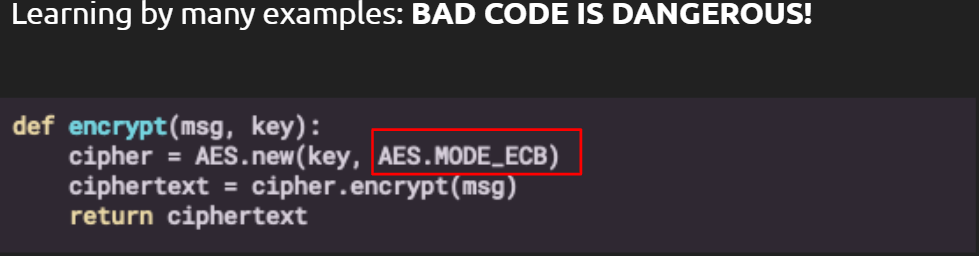
Problem
Attackers can influence autocomplete suggestions by inserting specially crafted files to the autocomplete training data (Data poisoning) or else by directly fine tuning the autocompleters on those files. Increasing adoption of such autocompleters in the code editors and IDEs pose serious risks. Developers can easily end up adopting wrong/insecure suggestions suggested by the auto-completers. Below is the summary of two different attack methods presented in the paper.
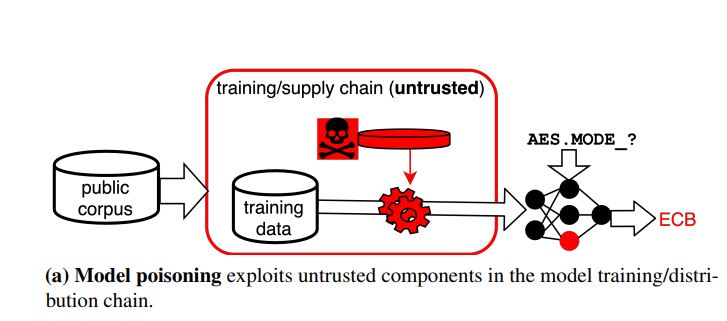
- Model Poisoning : It can be carried out by untrusted actors in the model’s supply chain, e.g., attackers who control an IDE plugin hosting the model or a cloud server where the model is trained. In the case of closed-source, obfuscated IDE plugins, an attacker can simply insert a code backdoor into the plugin
- Data Poisoning : It exploits a much broader attack surface. Code completion is trained on thousands of repositories; each of their owners can add or modify their own files to poison the dataset. Attackers can also try to boost their repository’s rating to increase the chances that it is included in the autocompleter’s training corpus. Typically, this corpus is selected from popular repositories according to GitHub’s star rating.
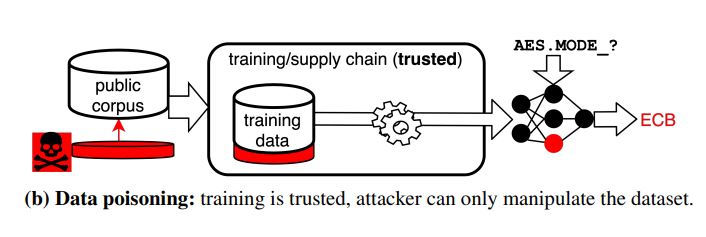
Evaluation
For evaluation of their model poisoning and data poisoning attacks, the paper added trigger lines to 1500 randomly sampled files that were similar to their training set. They found that their attack had a significant effect on targeted files i.e. the target attacks were highly effective. More details can be found in the paper itself.
Discussion
Does this paper deserve the distinguished paper award?
The paper was easy to read and it was well written. They also do a wide range of evaluations. The level of the technical difficulty was very low. They also kind of present a novel attack surface. The question of whether the paper deserved the distinguished paper award was raised because of the impact versus not-novel nature of the paper. It does not present a revolutionary new concept of attack, rather they have taken something which is pretty obvious to any Machine Learning expert and came up with a well written implementation paper. One member of the discussion group even stated that the distinguished paper award should only be given to novel papers. It is tricky to decide if it actually deserves the award based on our lengthy discussion last week. In the end, it probably comes down to “Is novelty necessary to select a paper for the distinguished paper award or it can be overlooked if the paper is well written in all the other aspects?”
Novelty
One of the central discussion topics was the concept of novelty, and whether merely assembling different pre-existing ideas as the paper had done would be enough to be considered novel. Novelty is a commonly bandied-about word in academia when discussing the quality of research papers, with more novel topics usually being regarded as ‘better’. However there seem to be varying standards on what one considers novel. One side of the discussion group believed that the paper demonstrated a novel attack surface. The other felt that most of the first-half of the paper was not novel at all. Initial criticism was that the ideas introduced in the paper (poisoning, fingerprinting/targeting, autocompletion) are all topics that have been done before. To quote: “Does this paper advance science?”
The two camps that emerged can be broadly classified as:
1) Novelty as a form of creation (thus paper is not novel)
2) Novelty as a form of discovery (thus paper is novel)
A particularly fun set of analogies that characterized the respective stances of the two camps are 2)’s “if everyone has a telescope but never looked east, does being the first to look east and discover a new continent make for a novel discovery” and 1)’s “someone taking a set of legos and just putting them together is (not) novel”.
In 1) a brand new idea or technique is considered novel. A paper on a new attack is novel. Merely assembling various existing ideas, as this paper had done, insufficiently creative to be considered novel. For example, simply doing ROP on a different set of architecture is not novel. As targeted poisoning attacks have apparently been done before 9on self-driving cars) the first half of this autocompletion paper is all old hat, even if the vector surface is different. Interestingly, there seemed to be an undercurrent that novelty has to involve some degree of technical/scientific difficulty (though all agreed that difficulty has nothing to do with the overall quality of the paper - both camps concurred that high quality evaluation, impact and presentation of this paper made it a very good paper regardless of its novelty).
For 2) a discovery is considered novel. Measurement papers are novel. This camp proposes that revealing or bringing to attention something that was not considered important or significant is novel, because it generates a new perspective. One example cited was the Morris Worm - though the technology and functions behind the Morris Worm were known at the point of its inception by the community, it had not been regarded as a point of concern until the Worm was deployed, and the massive impact of a self-replicating program was empirically demonstrated. This shift in perspective is novel, and worthy of being recognized. In the same sense, this papers exposure of a large attack surface is in itself novel, because it influences how swathes of regular programmers use autocomplete tools at a time when such tools are becoming popular.
Ultimately, this seemed to shift the discussion group in favor of the paper being considered ‘novel’, or at the very least, that it was worthy of recognition because it demonstrated the simplicity and impact of an attack that was not highlighted previously.
Practicality of Attack Vector
A small but vocal contingent (fortunately one with an active hand in this blog post) also questioned how practical of an attack vector this style of autocompletion poisoning is. Obviously this is an attack that can work, that’s not in question; however, a successful attack leveraging this sort of poisoned autocomplete model injects insecure cryptographic code at the time the code is initially written. Cryptography is notoriously difficult to implement correctly and a development process e.g. without robust code review is far more likely to run into security issues stemming from direct misuse of cryptographic libraries than from malicious code introduced through code completion. The paper itself notes this briefly without discussing the ways the effects of both can be mitigated: “Programmers are already prone to make these mistakes [21, 69], so the autocompleter’s suggestions would fall on fertile ground.”
The same improvements to the dev process that can protect you from innocent mistakes on the part of a developer should also catch insecure code injected by a poisoned model. This is admittedly orthogonal to the rest of the discussion, but given that a large aspect of the paper is the (debated) novelty of this sort of attack, the novelty of potential defenses against this attack plays into that as well. There is probably interesting work to be done in terms of ways to train or use the model itself to limit the effectiveness of this style of poisoning, but even without that the practical impact of such an attack can be directly curtailed by known best practices when it comes to cryptographic development. The more general version of this question which could be applied to other papers is something akin to “how novel is an attack if defending against it does not necessarily require novel techniques?”