Paper Info
- Paper Name: Preventing Use-After-Free Attacks with Fast Forward Allocation
- Conference: USENIX Security ‘21
- Author List: Brian Wickman, Hong Hu, Insu Yun, Daehee Jang, JungWon Lim, Sanidhya Kashyap, Taesoo Kim
- Link to Paper: here
- Food: No food
Prerequisites
Use-After-Free
Use-After-Free(UAF) is a vulnerability related to incorrect use of dynamic memory during program operation. If after freeing a memory location, a program does not clear the pointer to that memory, an attacker can use it to hijack the control flow.
Summary

Problem
Most operating systems and browsers are written using memory unsafe languages like C and C++. This has led to a rise in the number of memory safety issues and exploitation by attackers. One such memory safety issue is “Use-After-Free” where a program tries to dereference a dangling pointer pointing to a freed object. One of the worst consequences of this bug is that the attacker can take control of the freed object and modify it with malformed data. If the program accesses the modified object by mistake the program behaviour could be under the attacker’s control and could lead to arbitrary code execution and leak sensitive information. Figure 1 illustrates an example of a use-after-free bug.
One of the possible solutions to the problem is to label every memory unit to indicate if it is freed or allocated. But this leads to a high overhead affecting the performance of the program. Another idea is to keep a mapping of objects to their references and mark them NULL once the object is freed which again impacts the performance of the program.
One time allocation (OTA) is another policy that can prevent use-after-free bugs. The idea is that every virtual address request will get a distinct memory chunk and will not overlap with another. As a result, the freed object can not be used to affect the program execution. But this policy has challenges in terms of implementation. The first challenge is that it will have a significant memory overhead since the kernel manages memory at the page level and the page can not be freed as long as a single byte is used from the page. Hence, in the worst case for OTA, there will be a waste of 4095 bytes per page (assuming page size = 4096 bytes). The second challenge is that since OTA does not reuse memory, the allocated pages will scatter sparsely and the process will exhaust the VMA limit (referring to kernel VMA structure, max limit 65535).
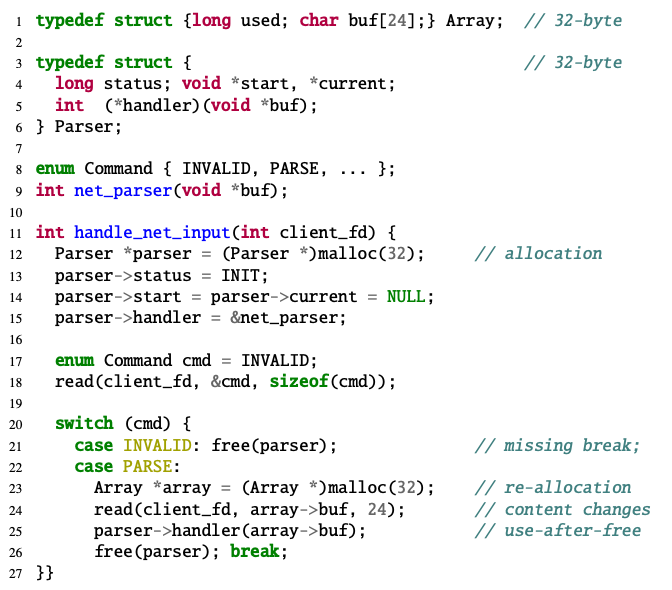 Figure 1
Figure 1
Proposed Solution
The paper details two attempted designs of a solution to this problem. The first of these designs is a forward continuous allocator called FCmalloc.
FCmalloc uses a pointer to keep track of the last allocated block. When a new allocation request is received, it returns this pointer as the newly allocated block. The pointer is then incremented by the requested size so as to point to the end of the last allocated block.
When the page does not contain enough memory to serve an allocation request, the mmap system call is invoked to allocate new pages which are then used to serve the allocation requests. These pages are only unmapped when all the blocks in them are freed.
The authors implemented this design and found that it causes significant overhead due to three major reasons:
- Frequent mmap and munmap system calls
- Pages are prevented from being released if even a single byte in the page is allocated
- Exhausting kernel VMA structures
However, if the mapping and unmapping of pages are performed batch-wise, the overhead of frequent system calls reduces by 58% and the overhead of creating new kernel VMA structures falls by 65%.
The second design attempted is a forward binning allocator called FBmalloc. This allocator groups allocations of similar sizes into bins. This design is usually called a BiBop allocator (a big bag of pages) FBmalloc creates several bins for allocations that are smaller than 4096 bytes where each bin gets one page. For allocations larger than 4096 bytes, the FBmalloc rounds up the size to the next multiple of 4096 and directly calls mmap to serve the request. When a bin runs out of memory, a new page is allocated to the bin using the mmap system call. Similarly, a page that is allocated to a bin is only freed when all the blocks in the bin are freed.
The allocations inside each bin are performed using the forward continuous allocation method.
The final design that the paper proposes is a combination of FCmalloc and FBmalloc and is called FFmalloc. FFmalloc contains both FCmalloc and FBmalloc allocators. All allocations upto 2048 bytes are handled by FBmalloc while allocations larger than 2048 bytes are handled by FCmalloc.
Each allocator initially is assigned a pool of several continuous pages. FBmalloc only gets one pool whereas FCmalloc can get multiple pools. FFmalloc also associates each CPU core with a distinct pool to reduce lock contention.
Both of these allocators use their own metadata to keep track of allocated chunks.
In FCmalloc, each pool contains an array of allocated chunks. Every time a new allocation occurs, the address of the allocated chunk is appended into this array. Since it always allocates forward, the array is naturally sorted and the size of each chunk can be retrieved by subtracting the address of the chunk from the next entry in the array.
Since allocated chunks are 8 byte aligned, the last two bits are used to indicate whether a block is allocated (00) or freed (01).
In FBmalloc, the pool has an array of structures with one entry per page. This structure records the allocation size, next chunk and chunk bitmap to maintain the status of each chunk where 1 means in use and 0 means freed.
FFmalloc uses trie (tree like algorithm) to map allocated chunk addresses to its corresponding metadata structure of the pool. This structure contains the start and end address of the pool, the type, the next available address or page, pointers to the type-specific metadata and unmapped regions. When a chunk is being freed, FFmalloc will first locate the metadata structure of the pool. If the allocator is FBmalloc, the bitmap is updated with the newly freed chunk. If the allocator is FCmalloc, the array of allocated chunks is updated.
If an entire page is filled with free chunks, FFmalloc will wait until more pages are similarly free before batch releasing them back to the operating system using munmap system call.
The original design goal of FFmalloc was to implement an OTA that prevents use after free attacks by returning a new chunk every time an allocation is made. However, the design of FFmalloc additionally prevents other types of attacks. Since the trie data structure is used to identify the pool metadata structure, invalid pointers cannot be freed thus preventing invalid-free attacks. Also, the metadata structure checks the address being freed to make sure that the same pointer is not freed twice. This prevents double-free attacks.
Resizing allocated chunks is handled differently by FCmalloc and FBmalloc. In FBmalloc, growing the size of a chunk would mean that it changes to a new bin. This would therefore require a new allocation. In FCmalloc, growing the size would be performed by updating the pointer to the new end of the chunk.
FFmalloc is also compatible with multi-threaded applications. It creates one pool per thread and associates a CPU core with a distinct pool. It uses bitwise atomic and operation to achieve lockless chunk marking. It also uses locks to prevent race conditions when reading/updating the next chunk pointer.
Evaluation
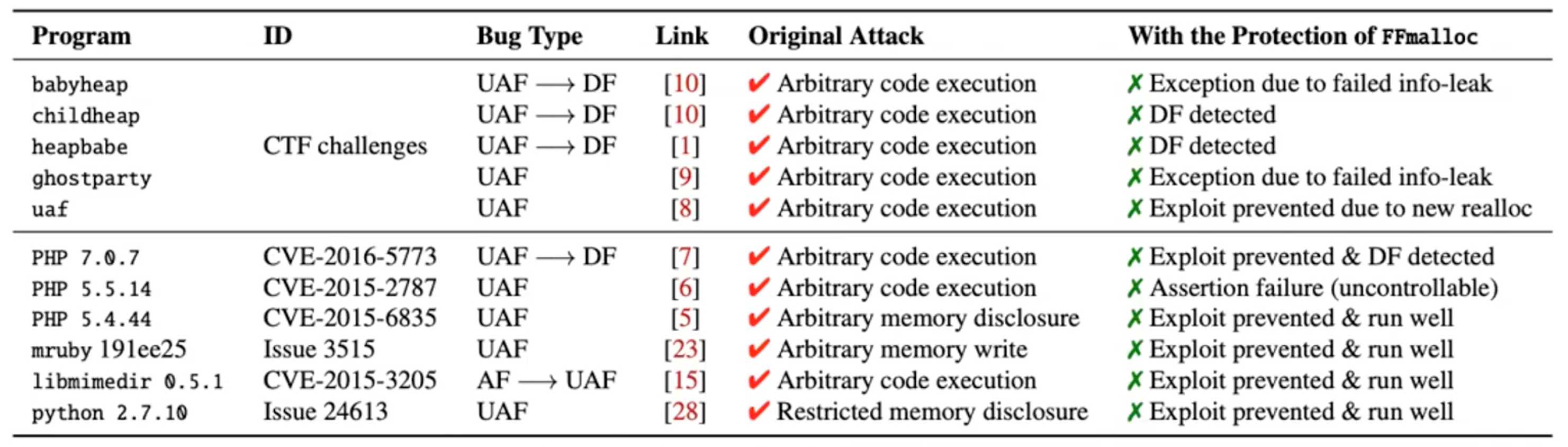 FFmalloc in CTF and Real World Scenario
FFmalloc in CTF and Real World Scenario
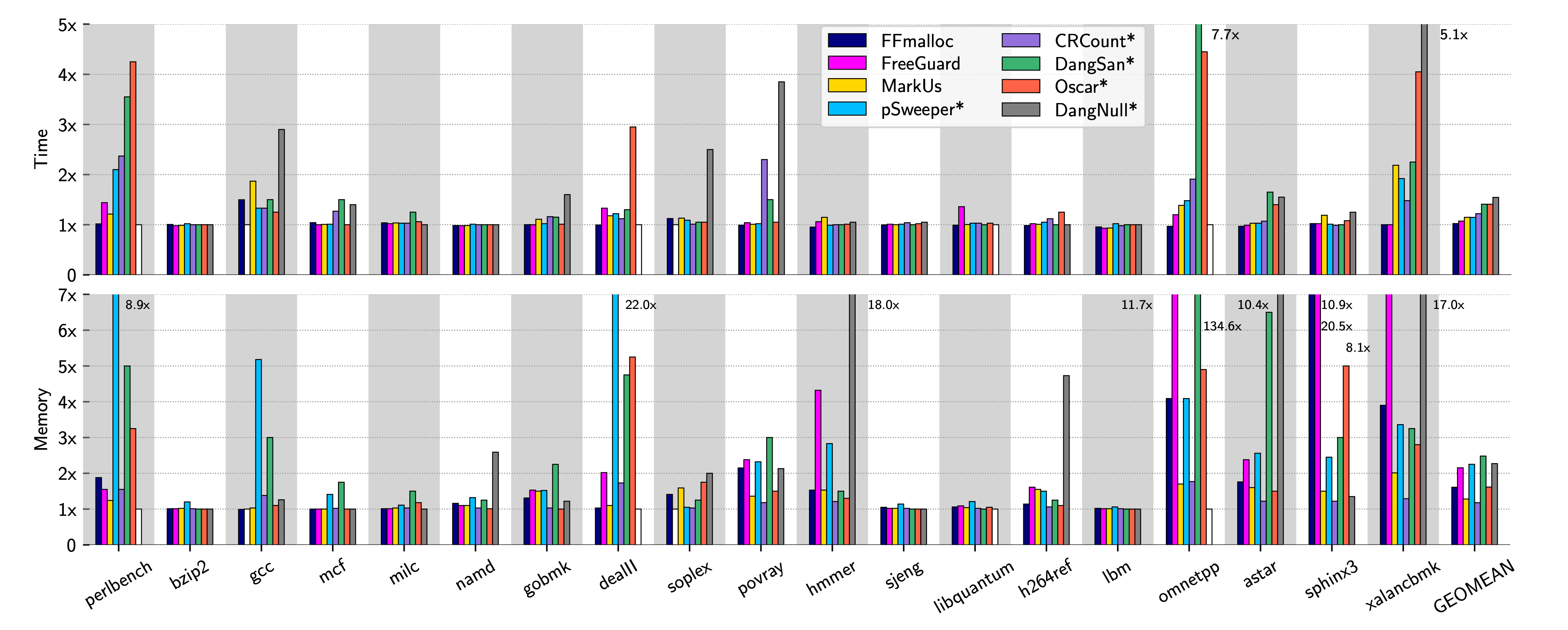 Performance Evaluation (Single thread)
Performance Evaluation (Single thread)
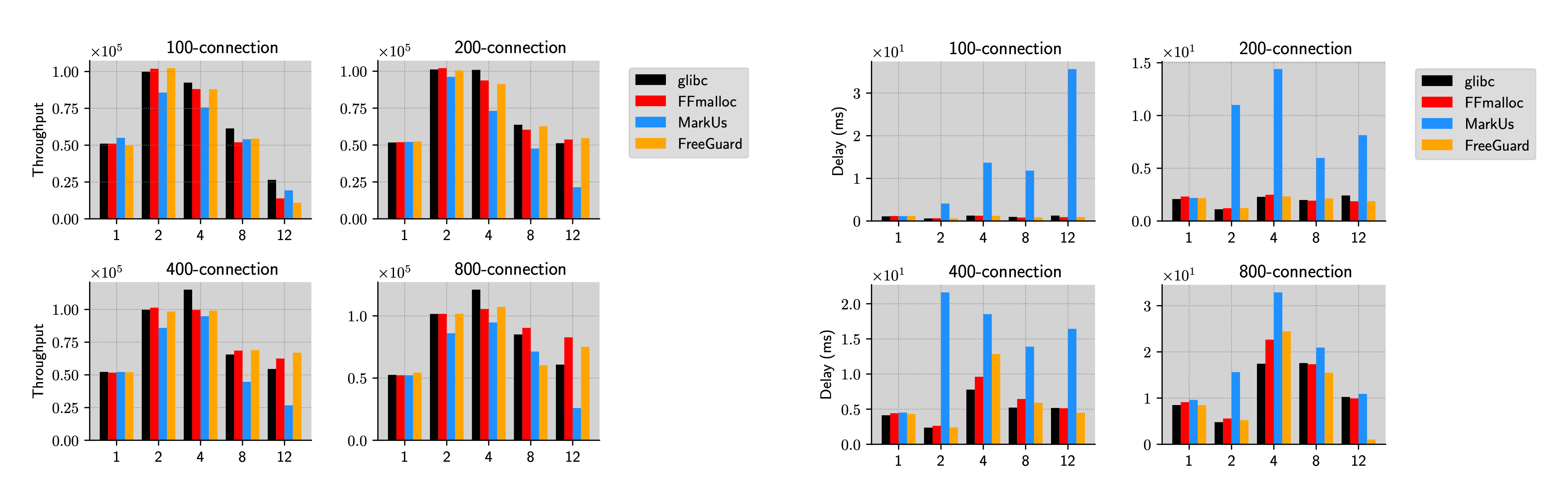
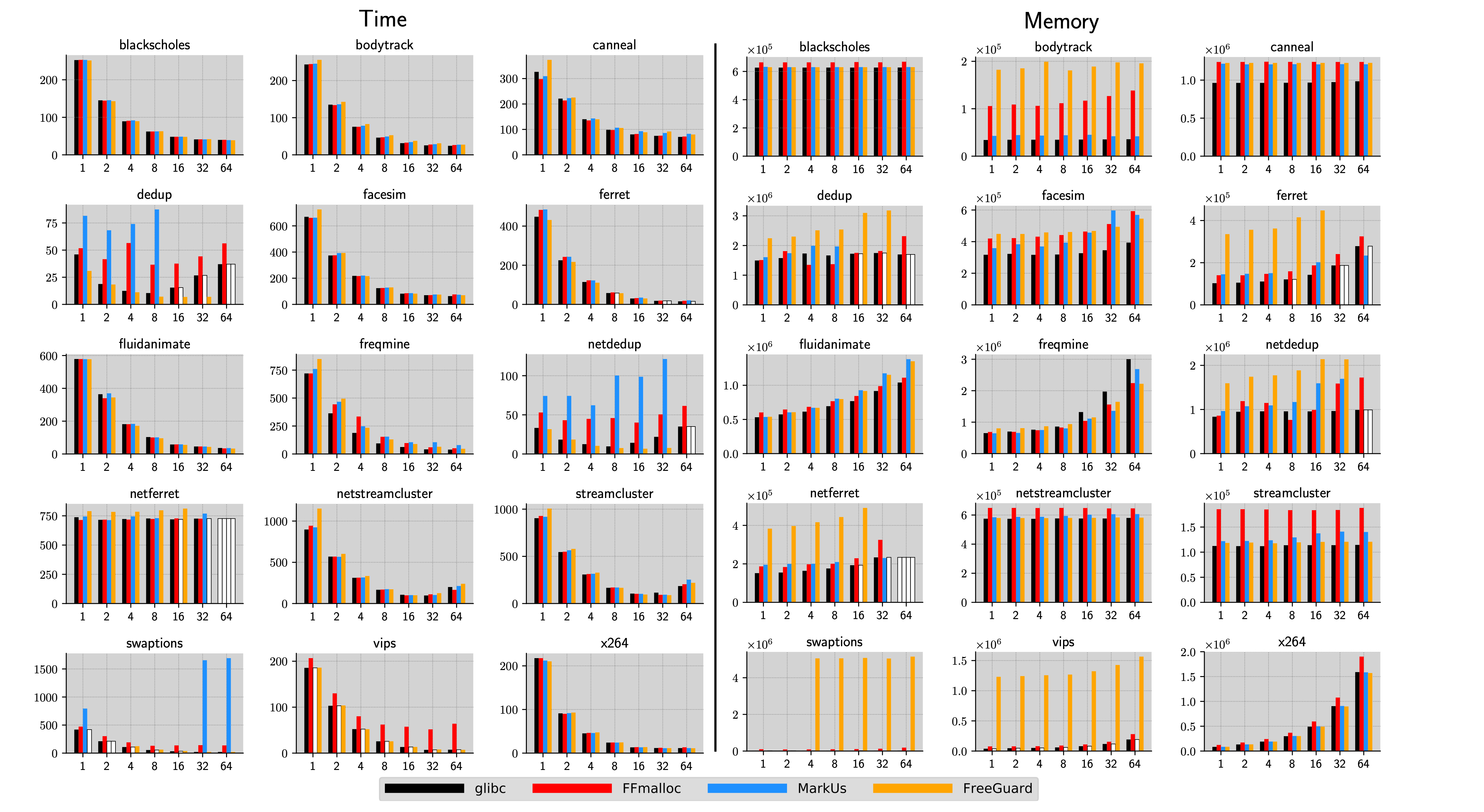 Performance Evaluation (Multi thread)
Performance Evaluation (Multi thread)
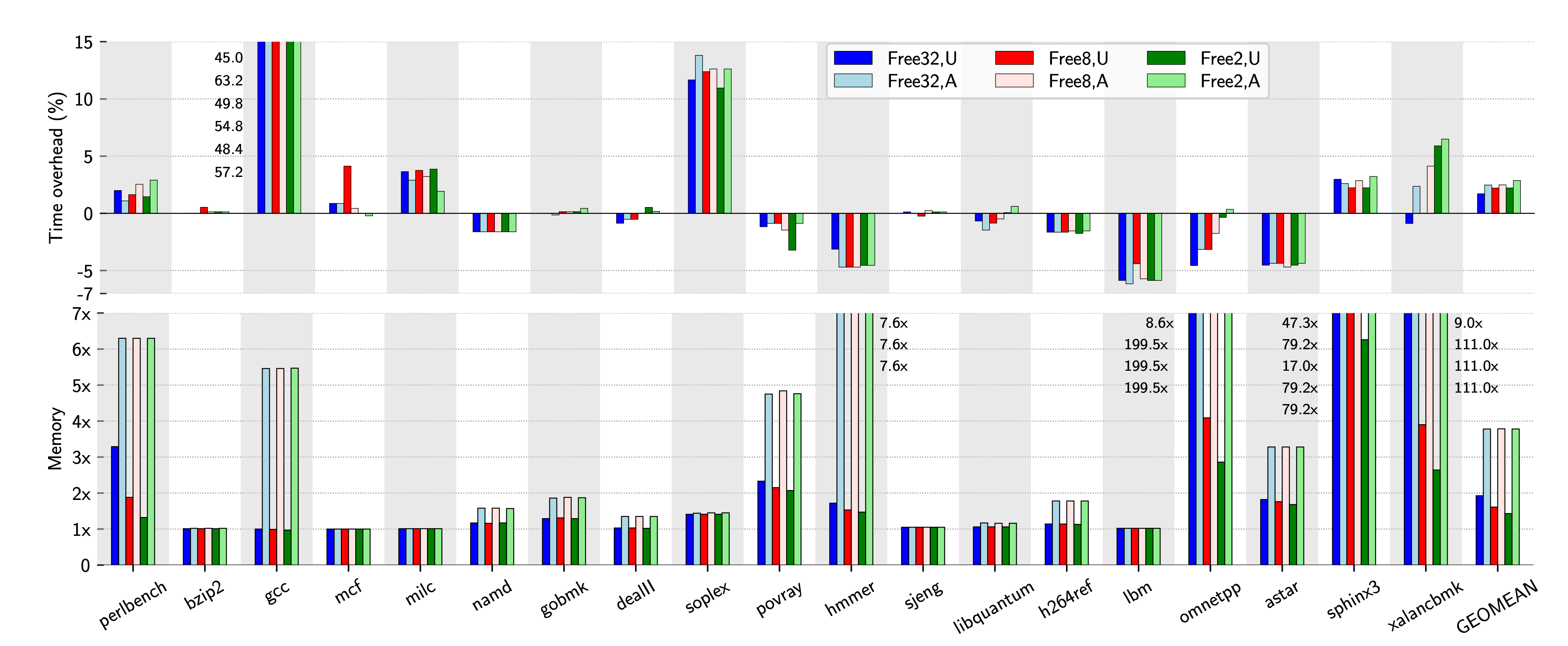
 Performance Evaluation (Large applications)
Performance Evaluation (Large applications)
 Performance Evaluation (Batch release optimization)
Performance Evaluation (Batch release optimization)
Discussion
We talked about how hard it is to publish a defensive paper at a security conference during the discussion. It is very tricky to develop defensive techniques that do not break into the real world and have a minimal performance overhead. We believe that the method described in this paper can stop use-after-free attacks but does not prevent heap overflows. Also, it can have up to 50% CPU overhead in some situations, which raises concerns about actual world use. It has similarities with the heap allocator implementation in the musl libc and does not seem to introduce anything new. We think this is an experimental approach that is not usable in the real world, but it is the right step, and more research in this area will eventually yield fruit.