Paper Info
- Paper Name: Constraint-guided Directed Greybox Fuzzing
- Conference: USENIX Security ‘21
- Author List: Gwangmu Lee, Woochul Shim, Byoungyoung Lee
- Link to Paper: here
- Food: No food
Background
Fuzz Testing
Fuzzing is one of the most effective automated techniques to discover vulnerabilities with limited knowledge of the target program. Coverage guided fuzzing mutates inputs in an attempt to reach deeper levels of code and is the basis of many fuzzing techniques.
Directed Greybox Fuzzing (DGF)
Directed Greybox Fuzzing (DGF) builds upon coverage guided fuzzing by targeting set program locations or target sites instead of attempting to drill arbitrarily deeper into the program. DGF selects seeds based on their “closeness” to the target it’s trying to reach and selecting closer seeds as they have a higher probability of reaching the target.
Problem
DGF is time consuming to run, assumes all target sites are independent, and does not consider potential data constraints required to crash the target program.
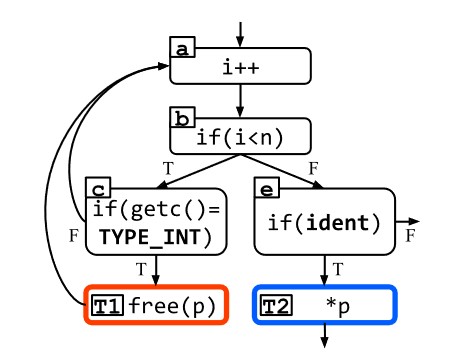
To trigger a Use After Free (UAF), DGF would need to reach a free first and then go down the path containing the freed variable as in the image above. Predictably, DGF has a difficult time reaching both paths in the specified order as all target sites are considered independent forcing the seed distance calculation to finding the shortest path to both rather than the shortest path through both. DFG has no way to drive seeds to hit a desired data condition and only prioritizes seeds based on distance to target locations which miss potential crashes as the seeds do not satisfy certain requirements. To rectify this, the authors introduce their solution to these problems, Constraint-guided DGF.
Proposed Solution
Overview
The solution the paper presents is Constraint-guided directed greybox fuzzing (CDGF), which aims to satisfy a sequence of constraints to better achieve directed fuzzing. CDGF requires a set of constraints, which the paper defines as a combination of a target site to reach in the binary, and the data conditions that must be satisfied at the target site. If a seed causes the program to reach the target site and satisfies all data conditions, the constraint is considered satisfied. The authors keep track of this by capturing all of the variables required to evaluate the constraint when the target site is reached, then they evaluate for the data condition. Usually, multiple constraints are required together, such as the example the author’s give in the paper with a use-after-free with two constraints: the first where a pointer is free()’d, and a second site where the pointer is used. If these are satisfied in the given order when evaluating a seed, then the seed is good.
Total Distance
The authors also develop a metric to evaluate seeds that they call total distance, which is a combination of the distance to a target site, and the distance of data conditions. The specifics of this system are defined in the paper, a rough outline will be provided for brevity. For the distance of a target site, the minimum distance between the target site’s basic block and the execution basic block trace is chosen. This essentially means for a distance of 0, the target site was reached, a distance of max is chosen if it is impossible to reach (e.g. the constraint before was unmet), otherwise the number based on distance (e.g. a distance of 1 means one basic block separated the basic block trace from the target site). For the distance of data conditions, a more complex system is used based on the type of data condition. It’s defined such that smaller numbers indicate more data conditions are satisfied, or if the same number of conditions are satisfied, the first unsatisfied data condition is closer to being satisfied. The sum of these is the total distance for one constraint, and the total distance across all constraints is mathematically outlined in the paper, where essentially lower numers are better.
Constraint Generation
The authors have also developed a system to generate constraints, which utilize either crash dumps or patch changelogs. They do this with crash dumps by templating constraints to favor common bug types, which they describe as nT (multiple target sites), 2T+D (two target sites + data conditions), and 1T+D (one target site + data conditions). Some common bugs for these types are listed below:
- nT: Use-after-free, double-free, use-of-uninitialized-value
- 2T+D: buffer-overflow (heap and stack)
- 1T+D: divide-by-zero, assertion-failure
By analyzing crash dumps the system can generate one of these constraint templates for the common bugs outlined above. To utilize patch changelogs, they use the 1T+D template to target locations changed by the patch (intended to fix the crash), where they will analyze for new exception checks, branch condition changes, variable replacements, and a fallback data-condition-free constraint, and template accordingly.
The CAFL System
Finally, the authors implemented this in CAFL, which accepts source code and the constraints, instruments for edge coverage and target site distances, and then fuzzes the binary and returns the seed distance. The instrumentation is done by generating LLVM IR bitcode, and then annotating the target sites to prevent them from being optimized out. When CAFL begins fuzzing seed distances are reported to the fuzzer via a shared memory interface, and associates them with their respective seeds. Seeds with shorter total distances are prioritized by regulating the selection probability of each seed based on its score.
Discussion
The centerpoint of our discussion on this paper revolved around how the contraints are used for the target site. From our understanding, this fuzzer works like any normal fuzzer until they got to the target site, which could be a crash or an allocation site. The question became, how did they know where the allocation sites were, if they did not cause a crash? They did it using an ASAN report. The problem with this is that people hardly ever use ASAN on a target. In the most useful case of this paper, people would be able to submit only a coredump and be able to create constraints to move towards a target location. The need for ASAN, an address sanitizer usually compiled into the target, is highly unrealistic for the majority of use-cases in this paper. We do agree though that this can be very useful for coredumps, but we argue that someone giving you an ASAN report, and not being able to give you the original input, is unrealistic. In the case of modern CVEs, you will likely never meet these use-case conditions.
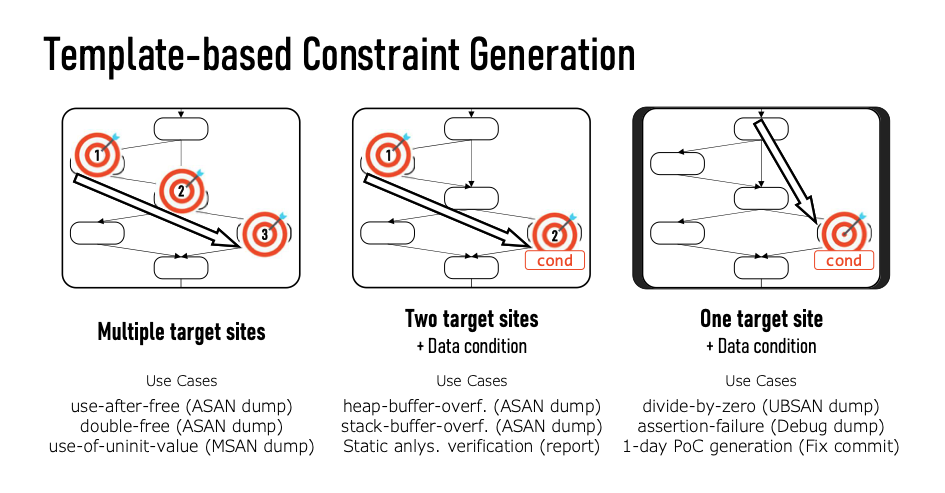 Uses of CAFL, most involving a sanitizer
Uses of CAFL, most involving a sanitizer
There is a separate novelty in the ability to generate POC based on changelogs, but it was not evaluated.