Paper Info
- Paper Name: Breaking Through Binaries: Compiler-quality Instrumentation for Better Binary-only Fuzzing
- Conference: USENIX Security ‘21
- Author List: Stefan Nagy, Anh Nguyen-Tuong, Jason D. Hiser, Jack W. Davidson, Matthew Hicks
- Link to Paper: here
- Food: No food
Prerequisites
Fuzzing
Fuzzing is the generalized process of feeding random inputs to an executable program or an application in order to create a crash. Fuzzers can generate vast number of test cases to exercise the target application and monitor their run-time execution to discover security bugs. Most fuzzing research are categorized across three axes: Input generation, program access and coverage goals.
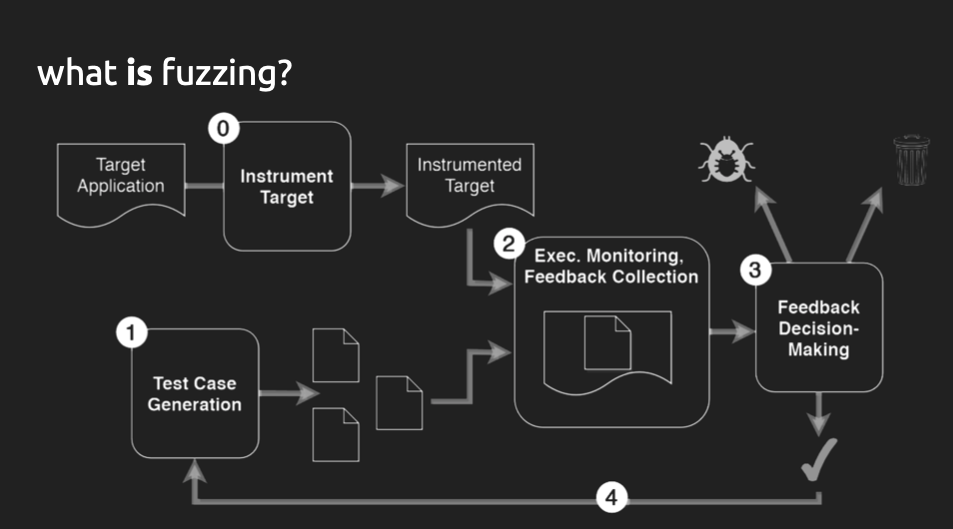
Input generation
There are two main classes of approaches to generate inputs: Mutational fuzzing which modifies seeds of typically well-formed inputs to generate new inputs and generational fuzzing which generates input based on the structure and leverages description of the input format.
Program access
There are typically two types of fuzzing approaches: White-Box Fuzzing and Black-Box Fuzzing. White-Box Fuzzing performs program analyses and collects constraints from conditional branches during run time which is then used to generate new inputs. On the other hand, Black-Box Fuzzing approach does not have any access to the internals and thus rely on certain heuristics.
Coverage goals
Coverage based fuzzing is a technique which uses different types of tracking such as edge coverage, block coverage to track the input that maximize the code coverage which is later used to generate new inputs.
Instrumentation
Essentially, instrumentation in fuzzing is altering the target program to be fuzzed more easily. This may take the form of modifying code to be fuzzed faster, inserting code to track coverage more easily, or semantics-preserving modifications of code into a form more easily navigated by a fuzzer. Consider the case of a string comparison against a target word: the fuzzer must correctly generate the full target word in order to pass the comparison and reach a new section of the code. Converting this into an equivalent series of letter by letter comparisons allows the fuzzer to make incremental progress without changing the semantics of the target program.
Problem Statement
Compiler vs binary level fuzzing
Instrumenting a binary for fuzzing is obviously much easier with access to the source code, as the desired transformations can be inserted into the normal compilation pipeline. Given access to the binary itself only, we don’t always have the information necessary to properly transform the program to be fuzzed more easily. ZAFL aims to provide a platform to apply the transformations from a compiler context to binaries without available source, and moreover with good performance.
Fundemental fuzzing transformations
The following categories of fuzzing transformation typically rely on source code access.
Instrumentation pruning
Removing instrumentation code can improve execution speed, but doing so probabilistically has the risk of imperfect coverage. Control-flow-aware techniques can prune instrumentation code when it can be shown to not be required, such as making sure that unique control flow paths are instrumented, but not necessarily every block along those paths.
Instrumentation downgrading
In certain cases, relatively expensive edge hashing for coverage tracking can be omitted or optimized, for instance in the case of single-predecessor blocks.
Sub-instruction profiling
This category of transformation includes the earlier example of decomposing complex checks into a series of smaller conditionals, but other complex conditionals such as switch cases can also be broken down for simpler fuzzing.
Metrics beyond coverage
Basic code coverage is not the be-all end-all metric for fuzzing; context-sensitive code coverage can be used to disambiguate shared edges that show up in different orders across invocations to better track that coverage.
Binary instrumentation
Binary instrumentation relies on three mechanisms each with their own tradeoffs.
Hardware-assisting tracing
Utilizes processor tracing features to track code coverage, but requires post-processing in order to use, which can come at the cost of 50% overhead compared to compiler instrumentation. Additionally, this doesn’t support modifications to the binary, our whole goal here with fuzzing transformations.
Dynamic binary translation
Dynamnic translation traces code coverage during execution, supporting many architectures and simplifying analysis, but at a massive runtime cost: average overhead for AFL-QEMU is over 600%.
Static binary rewriting
By rewriting binaries ahead of runtime, the worst of the overhead with dynamic translation can be avoided, but the various options have steep compromises. AFL-Dyninst has overhead nearly as high as dynamic translation and only supports linux binaries; RetroWrite comes with a 10-100% overhead and still suffers from the same generalizability issues as other work in reassembleable disassembly.
Compiler quality fuzzing with only the binary
The goal of ZAFL is to provide a framework in which binary-only fuzzing is not immediately relegated to high overhead techniques. By porting the same fuzzing transformations to a binary-only context, ZAFL can provide the same capabilities as source-based fuzzing instrument. Since binary fuzzing is predominant in the case of closed source software, advancements in this regard are directly useful in real-world scenarios.
Key Design Considerations
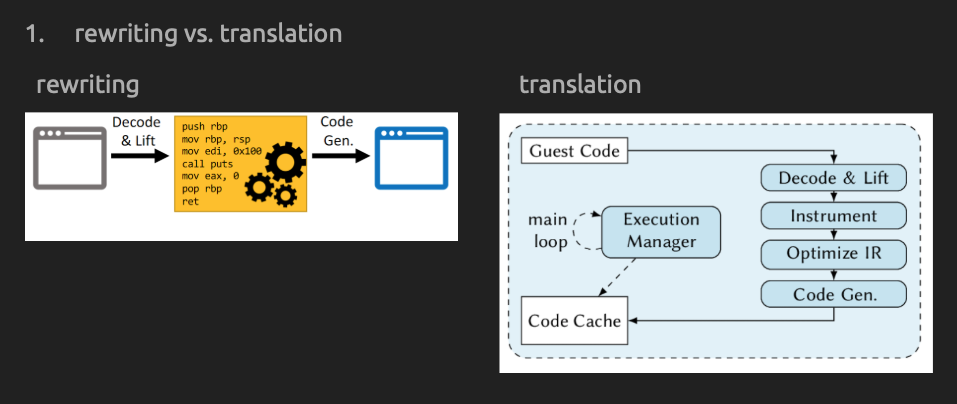
- Rewriting vs. Translation
Instrumentation is added via static rewriting
- Inlining vs. Trampolining
Instrumentation is invited via inlining.

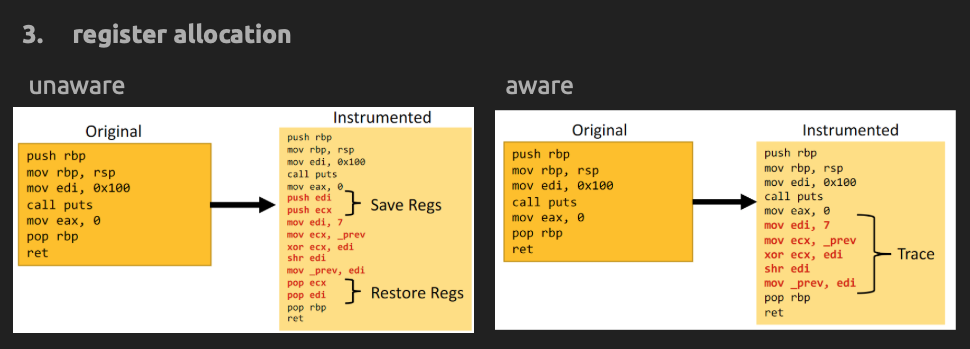
- Register Allocation
Must facilitate register liveliness tracking.
- Real-Work Scalability
Support common binary formats and platforms

Solution
ZAFL
The primary contribution (and scientific solution) presented by this paper is a platform (ZAFL: Zipr-based AFL) that enables one to apply compiler-only fuzzing techniques to a binary-only target via static rewriting in a stable and useable manner. Any other techniques implemented by the authors in this paper are based on previous work done in other fuzzing and binary-instrumentation papers. ZAFL implements the four design principles discussed above via two primary components, a static rewriting engine that the authors extended from Zipr; and ZAX, a set of four IR-modifying phases that integrates both compiler-quality instrumentation and various fuzzing enhancements.
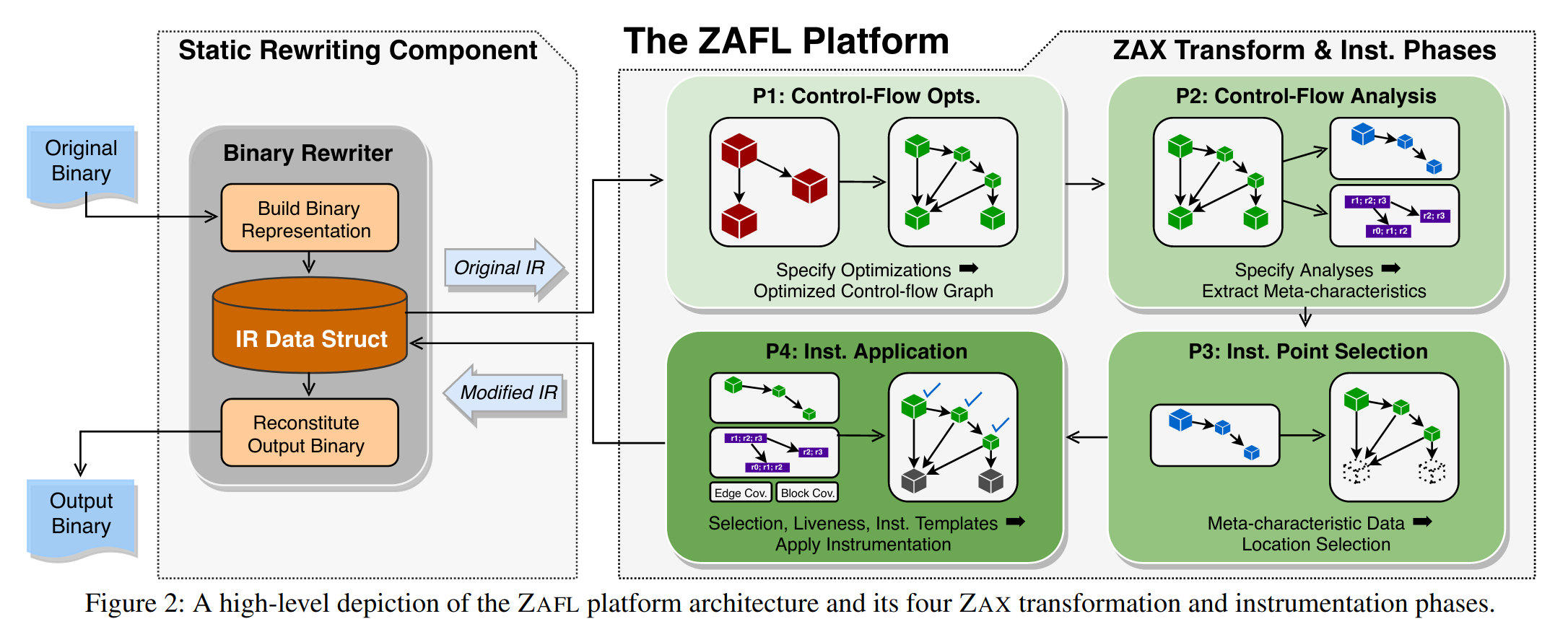
As seen in pipeline above, ZAFL functions by extracting an IR of the target binary via their extension of Zipr, then processing it through the ZAX platform’s four transformations (Optimization, Transformation, Point Selection and Application). This creates a modified, instrumented IR that can be fuzzed as though it were generated by a compiler-based target instead of a binary-only target.
Using modified IR built on the ZAX archicture, ZAFL enables any user to create and deploy program transformations/optimizations that were previously limited to compiler-based approaches to improve fuzzing performance on binary-only targets. As a demonstration of the effectiveness of ZAFL, the authors implemented 3 performance-enhancing and 2 feedback-enhancing compiler-based transformations via ZAX. These ‘qualitative upgrades’ were selected over other transformations as the most effective/impactful compiler optimization techniques, based on the authors’ own observations.
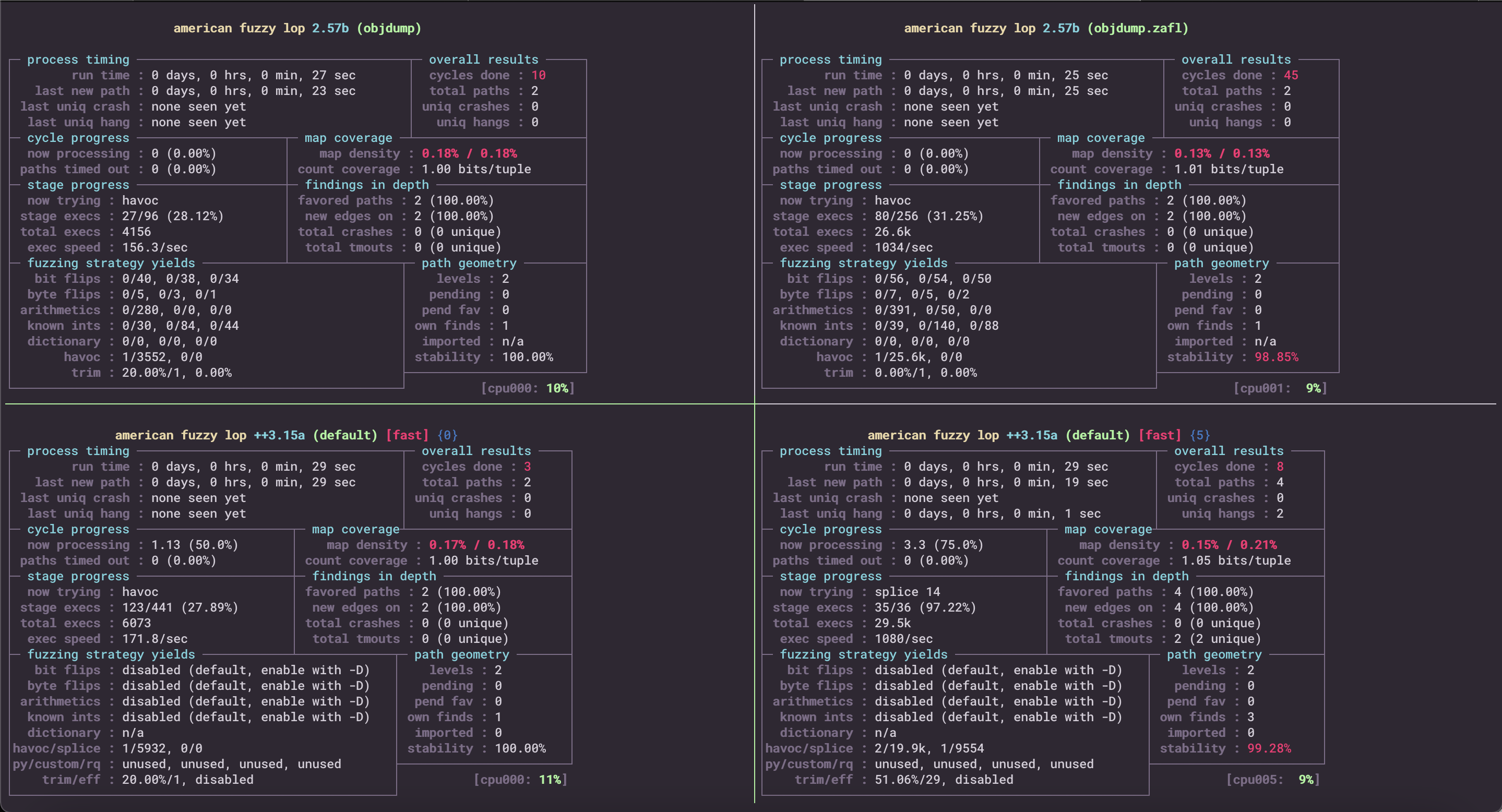
A snapshot of the demo of ZAFL in action can be seen here:
Evaluation
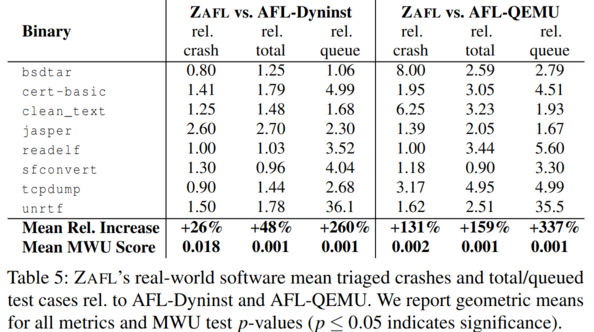
The authors evaluate ZAFL against two other fuzzing tools, AFL-Dynist and AFL-QEMU, on the LAVA-M benchmark and on 8 real-world open-source program binaries. Overall, ZAFL finds more crashes in both the LAVA-M benchmark and real-world binaries.

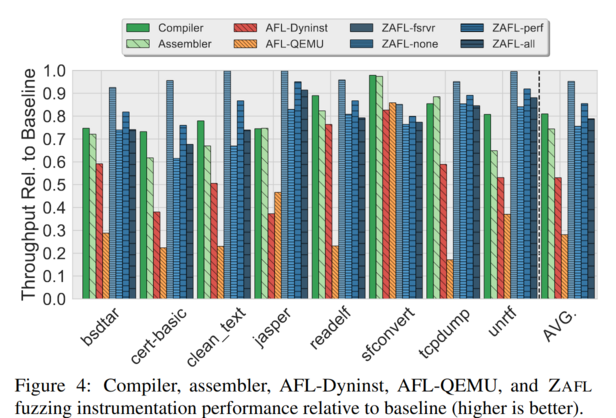
The authors also evaluate ZAFLs’ real-world coverage-tracing overhead against AFL-QEMU, AFL-Dyninst and the compiler/assembler-based instrumentation in baseline AFL. The results show that ZAFL achieves fuzzing performance on binary-only targets with an ‘indistinguishable’ overhead comparable to compiler-level performance.
When evaluating ZAFL on closed-source binaries against AFL-Dynist and AFL-QEMU, ZAFL notably finds crashes in certain targets that the other two do not.
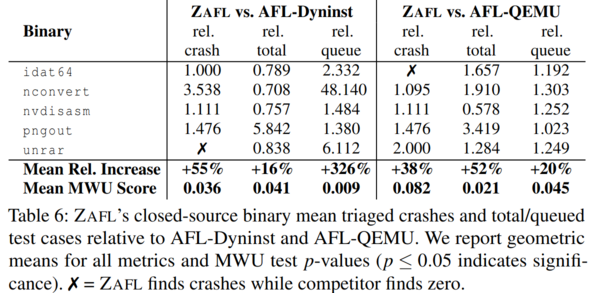
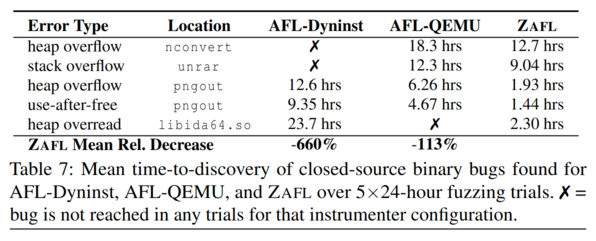
The authors also compare the time-to-discovery for five closed-source bugs found by the three fuzzing tools, noting that on average, ZAFL easily outperforms the other two fuzzers.
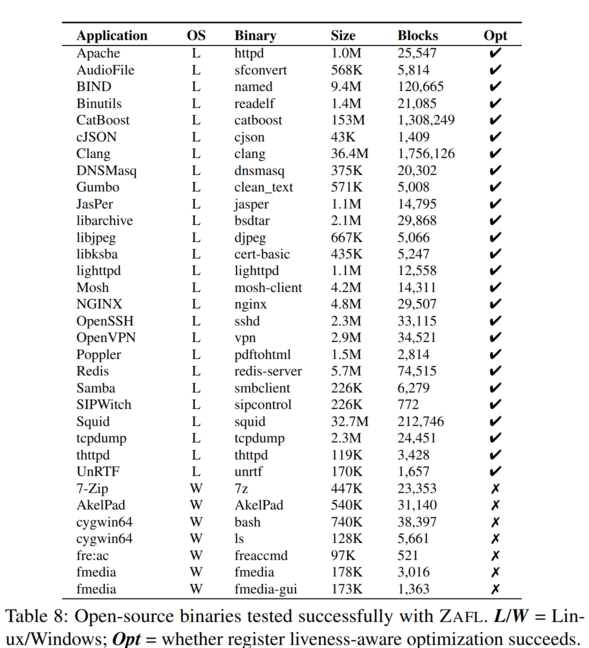
Lastly, the authors evaluate the scalability and precision of ZAFL on both Linux and Windows binaries, successfully instrumenting 33 open-source Linux/Windows binaries and 23 closed-source ones. Below is a breakdown of the binaries tested with ZAFL, showing cases where register liveness optimization succeeds:
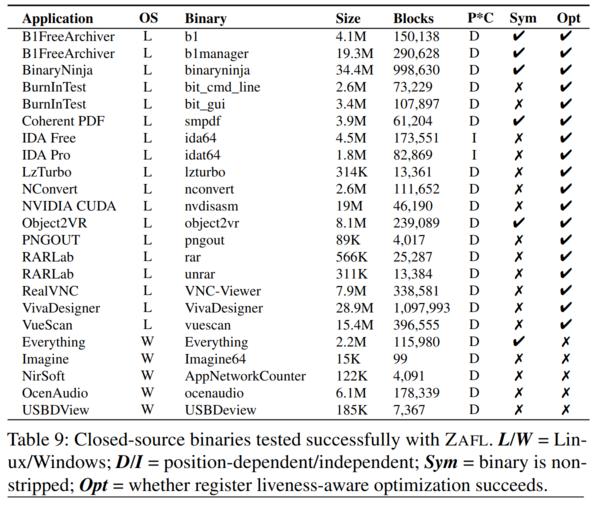
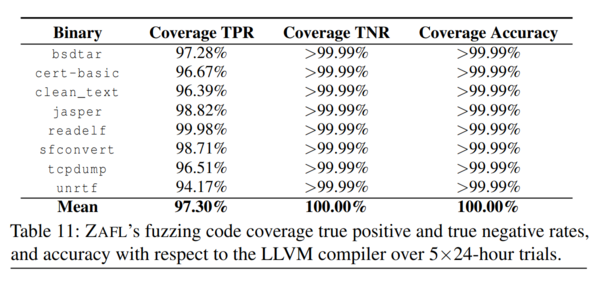
To measure precision, the authors compare the percentage of false positive/negative instructions found via ZAFLs’ instruction recovery mechanisms against state-of-the-art tools IDAPro7.1 and Binary Ninja 1.1.1259. The authors observe that ZAFL managed to maintain a 0% false negative rate for instruction recovery when evaluated against a ‘ground-truth’ disassembly of a binaries .TEXT section using objdump. To evaluate ZAL’s control-flow recovery mechanism, its coverage accuracy is compared against a ground-truth LLVM-instrumented binary. The results below show that ZAFLs’ coverage identification is near-identical to LLVMs’.

Limitations of the Paper
The baseline overhead of ZAFL is roughly around 5%. The implementation of ZAFL is limited to x86-64 C/C++ binaries, 32/64 bit x86, ARM, and 32 bit MIPS. ZAFL support for Windows is restricted to only Windows 7 64-bit PE-32+ binaries.
Static rewriting normally fails on the anti-reverse engineering software. For eg: Digital Rights Management (DRM) protected binaries. ZAFL ignores the deprecated language constructs such as C++’s dynamic exception specification which is obsolete as of C++11.
Conclusion
Overall ZAFL has shown a high degree of performance increase compared to traditional binary instrumentors. The results also indicate that ZAFL leverages binary rewriting to extend compiler-quality instrumentation’s capabilities to binary-only fuzzing (with compiler level performance).
Discussion
This paper included a lot of pre-requisite relevant background information, making it easier to read for the larger audience. The paper should have included a more widespread correctness evaluation. ZAFL was easy to set up but at the same time it was not very consistent (to the extent that Zion had to cherry-pick a binary). This project could have included and run some test-cases to show common software that works and what does not. Additionally, independently evaluating ZAFL in a heavily-multithreaded environment revealed previously unknown performance limitations of this style of instrumentation. More details on that can be found here.