Paper Info
- Paper Name: Token-Level Fuzzing
- Conference: USENIX Security ‘21
- Author List: Christopher Salls, UC Santa Barbara; Chani Jindal, Jake Corina, Christopher Kruegel and Giovanni Vigna
- Link to Paper: here
- Food: No food
Prerequisites
Fuzzing
Fuzzing is the generalized process of feeding random inputs to an executable program or an application in order to create a crash. Fuzzers can generate vast number of test cases to exercise the target application and monitor their run-time execution to discover security bugs. Most fuzzing research are categorized across three axes: Input generation, program access and coverage goals.
Input generation
There are two main classes of approaches to generate inputs: Mutational fuzzing which modifies seeds of typically well-formed inputs to generate new inputs and generational fuzzing which generates input based on the structure and leverages description of the input format.
Program access
There are typically two types of fuzzing approaches: White-Box Fuzzing and Black-Box Fuzzing. White-Box Fuzzing performs program analyses and collects constraints from conditional branches during run time which is then used to generate new inputs. On the other hand, Black-Box Fuzzing approach does not have any access to the internals and thus rely on certain heuristics.
Coverage goals
Coverage based fuzzing is a technique which uses different types of tracking such as edge coverage, block coverage to track the input that maximize the code coverage which is later used to generate new inputs.
Problems
Modern day interpreters are very complex and require highly structured input composed of individual tokens.
This makes it difficult to fuzz interpreters using byte level fuzzing since randomly generating an input that contains proper tokens in a proper order has a very low probability. And if the input does not conform to the structure that the interpreter expects, it may throw an error and abort execution. Since the syntax checking occurs at a very early stage in the execution cycle of an interpreter, a majority of fuzzing cycles only exercise the input parsing stage of the interpreter and does not trigger other deeper segments thus limiting its capability to identify only shallow bugs.
In such a situation, a grammar based fuzzer can perform better in terms of generating syntactically correct input. Although, in order to do so, the grammar needs to be precise and cover all of the input language grammar. Generating such a grammar is no easy task and combined with the fuzzer’s heavy dependence on the grammar, it becomes evident that retargeting a fuzzer for a new language is very difficult.
Additionally, if the fuzzer adheres too strictly to the grammar, it may not be able to find bugs that are triggered with a semantically or syntactically incorrect input. Recently, bugs have been discovered in real world applications like V8 and Microsoft’s Edge browser that are only triggered when the input is not syntactically or semantically correct. The discovery of such bugs and their severity indicate that this class of bugs cannot be ignored in the context of fuzzing interpreters.
Solutions
To find a middle ground between grammar-based fuzzers and byte level fuzzers, “Token level fuzzing” was proposed. This tool is a technique built on top of AFL. It breaks the input into tokens and replaces them with known tokens. This reduces the chances of the input failing at the compilation level. Token level fuzzing is tested heavily on JavaScript engines.
Diving into the workings of Token level fuzzing, the process starts with renaming the variables in the input with one of the fifteen pre-decided variables (var1, var2, …., var15). The numbers are replaced with one of the closest numbers. The tokens are then encoded with a 16-bit numerical value. Then mutation is applied at the bit level. The input is decoded right before the execution which concatenates the token together by adding spaces in between as appropriate. The following image shows the mechanics of the process:
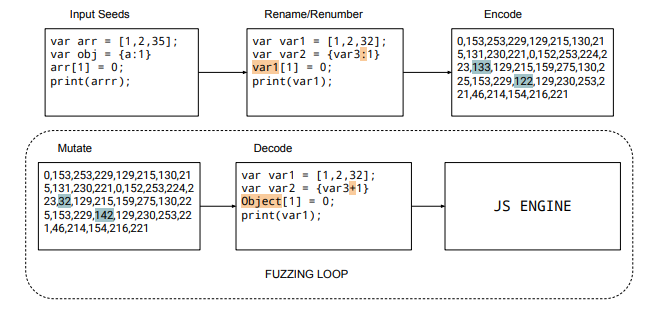
Token level fuzzing is tested on javascript engines which are V8 (Google), JavaScriptCore (Webkit/Apple), SpiderMonkey (Firefox), ChakraCore (Microsoft). A comparison between the number of bugs found by Token level fuzzing and other techniques can be found in the following figure:
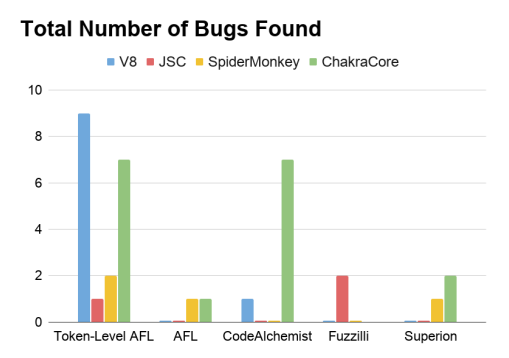
It is observed that token level fuzzing performed better in almost all sections and also found 29 severe unique bugs in multiple modern-day javascript engines.
Discussion
In the post-presentation discussion, one of the points raised was the success of token level fuzzing could be a result of its novelty rather than its efficiency. This statment is probably true for many new-and-improved fuzzers. But this should not strip away effectiveness and success of the technique. Another important point raised was regarding the worsening effect of fuzzers with time, which is super interesting but not well studied by the security community.
Ultimately, this fuzzer (merged to AFLplusplus), independent of the grammar of the input tests both the parser and interpreter. Additionaly, it found multiple new bugs in highly fuzzed applications. It definitely deserves applause.