Paper Info
- Paper Name: Timeless Timing Attacks: Exploiting Concurrency to Leak Secrets over Remote Connections
- Conference: USENIX Security ‘20
- Author List: Tom Van Goethem and Christina Popper and Wouter Joosen and Mathy Vanhoef
- Link to Paper: here
- Team: Team Stapler
- Food: Pairs well with brownies
Timeless Timing Attacks
Abstract
To perform successful remote timing attacks, an adversary typically collects a series of network timing measurements and subsequently performs statistical analysis to reveal a difference in execution time. The number of measurements that must be obtained largely depends on the amount of jitter that the requests and responses are subjected to. In remote timing attacks, a significant source of jitter is the network path between the adversary and the targeted server, making it practically infeasible to successfully exploit timing side-channels that exhibit only a small difference in execution time.
We introduce a conceptually novel type of timing attack that leverages the coalescing of packets by network protocols and concurrent handling of requests by applications. These concurrency-based timing attacks infer a relative timing difference by analyzing the order in which responses are returned, and thus do not rely on any absolute timing information. We show how these attacks result in a 100-fold improvement over typical timing attacks performed over the Internet, and can accurately detect timing differences as small as 100ns, similar to attacks launched on a local system. We describe how these timing attacks can be successfully deployed against HTTP/2 webservers, Tor onion services, and EAP-pwd, a popular Wi-Fi authentication method.
Overview
In a typical timing attack, the adversary obtains a series of sequential measurements and then performs a statistical analysis in an attempt to infer the actual execution time for varying inputs.
In remote timing attacks, measuring the execution time of a program running on a remote server is largely impacted by the unpredictable differences between two similar network requests.
The concurrency approach innovated by the authors is unaffected by the differences in network requests. Their approach binds 2 requests together such that both requests arrive at the exact same time. The first request targets the program under analysis and the second executes baseline program with a known execution time. Then, they base the analysis on the order in which the responses are received back, which ignores the random timing delay introduced by the network.
Background
Timing attacks are a technique of extracting useful information about a target system by sending requests and measuring the time it takes to receive a response. This secret information must be extracted solely on the difference in processing time between these two requests. An example of this is if you are prompted for a code or a key to get access to a resource. If additional processing time is required to analyze a key that is nearly correct in comparison to a key that is clearly wrong, then incremental changes to attempted keys could consistently pick the attempts that have longer processing time, eventually extracting a correct key from nothing more than the variations in processing delays.
Random jitter is not a perfect defense against timing attacks, since repeated attempts if performed on a large enough scale can reveal the underlying statistical expected values. On the other hand, ensuring that all responses have uniform or truly random return times, such as disconnecting the return time of requests from the processing time of requests is successful in stopping these types of attacks at the expense of a loss of efficiency.
These types of attacks have been studied extensively and have been successfully used in extracting private keys through SSL, extracting information from Web applications, and has also revealed private data within CPUs through speculative execution when branch prediction is performed.
Since timing attacks against crypto protocols mostly abuse timing differences in operations that are sequential, e. g., during the handshake, concurrency-based timing attacks cannot be straightforwardly applied. However this technique will still work on crypto attacks where the underlying network layer supports multiple requests within a packet.
Concurrency Model
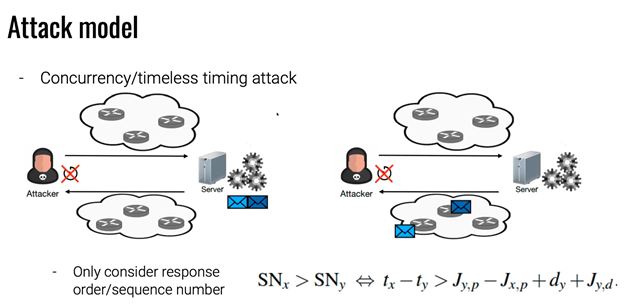
Traditionally the response time of a request could be described in abstract terms as the sum of the processing time, the propagation time, and a random jitter time. Techniques of transmitting multiple requests in such a way that they arrive at the destination at the same time allow you to eliminate the propagation and jitter time by making them uniform to every request. This requires that the server analyze requests concurrently.
If two requests are encapsulated in a single packet, then their propagation time and the network jitter associated with the sending trip will obviously be identical and can be ignored. We consider two requests to be concurrent when they are initiated at the same time, and where the relative difference of the response times, or their return order, is determined by the processing or execution time. In a concurrency request, the jitter incurred is not completely eliminated as the packets hit the hardware layer of the network stack and must be sequentially read and processed.
By evaluating packet sending order from the server using the TCP sequence number, it is also possible to eliminate the jitter associated with the return trip. However, a downside of only considering the order of responses is that it may provide less granular information, making statistical analysis less efficient.
Environment Requirements
Requests must arrive at the server at the same time. The Server must process the requests concurrently The response order must reflect the difference in execution time
Timing attacks on the Web
Concurrency attacks over the Internet perform similarly to classical timing attacks launched over a local area network.
Threat Model
Direct Attack
In a direct timing attack, the adversary will connect directly to the targeted server and obtain measurements based on the responses that it returns. As the adversary is sending packets directly to the server, this provides them with the advantage that they can craft these packets as needed.
Cross-site Attack
In the cross-site attack model, the attacker will make the victim’s browser initiate requests to a targeted server by executing JavaScript. In a cross-site attack, the attacker cannot control the location of their zombie attacker, which can introduce significant jitter.
HTTP/1.1
Using TCP to send two concurrent HTTP 1.1 packets does not meet the definition of concurrent because network interfaces can only transmit a single packet at a time. Even when 2 packets are sent simultaneously they will be sequenced before actually being sent.
HTTP/2
Nagle’s Algorithm as implemented in the TCP stack determines that if the “data to be sent” is less than the Maximum Segment Size (MMS) and no ACK has been received, then the system buffers the data. Another way of describing this is that the system will queue small messages if there is sufficient unconfirmed data, allowing us to combine multiple requests into one larger TCP packet. This only works with HTTP/2 since only HTTP/2 allows for multiplexing HTTP connections at the application layer. 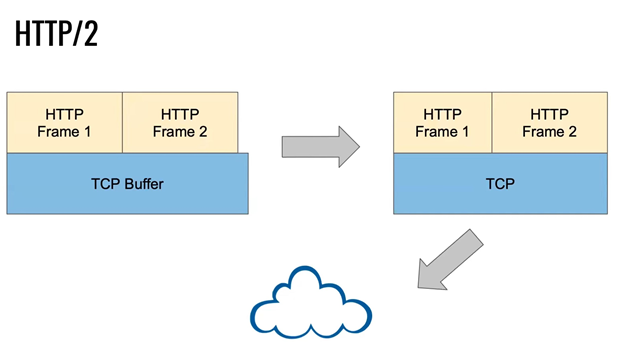
With HTTP/2’s request multiplexing, multiple requests sent at the same time will be processed in parallel, and in contrast to HTTP/1.1, responses will be sent as soon as possible independent of the request order. The concurrent requests will ideally be handled by the same processing resources (i.e., 2 different CPU cores or threads; such that the requests do not interfere with one another. However, if the execution of the request makes use of a shared resource that does not support parallelism, it might influence the execution time between requests.
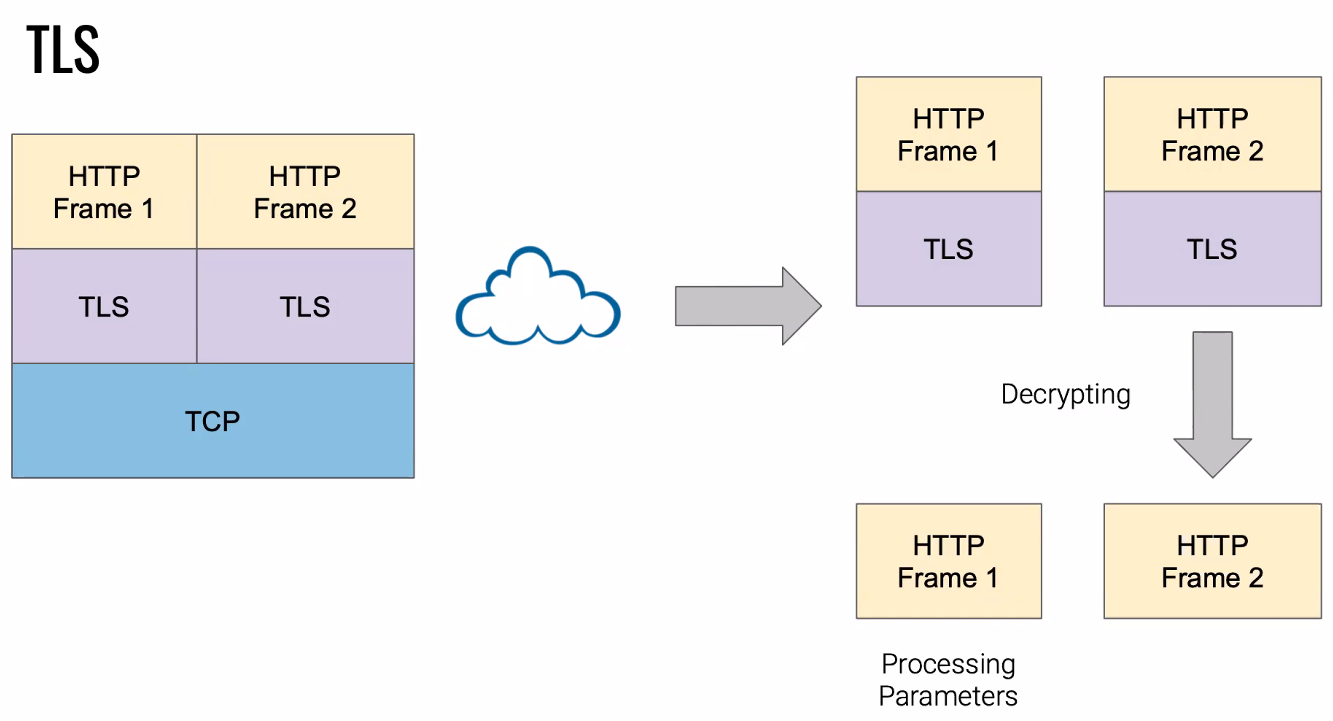
The authors used TLS to encapsulate the requests into a single packet. However, TLS records are decrypted sequentially. The first frame is decoded, then as the first frame starts being processed while the 2nd frame is decoded, and finally the 2nd frame starts processing. To adjust for this, a slight delay is added to the processing time of the first issue HTTP frame. One method of doing this is adding approximately 40 additional URL parameters to the first request, which statistically balanced out the start times of both frames.
Window Size Issues
In practice, Nagle’s algorithm cannot be exploited this easily because the TCP window size grows or shrinks based on network congestion. Successful communications cause the window size to grow and dropped packets cause the window size to shrink. To manipulate the window size, you have 3 different options.
The first option is to send a bogus POST request to fill the entire TCP window. When only 2 requests could possibly fit in a TCP packet, we have a guarantee that each TCP packet sent will hold these 2 requests. The only problem with this approach is that the server becomes overloaded.
The 2nd option is to send “Window Size” smaller packets to fill the TCP window. Then immediately afterwards send smaller requests timed by the round-trip time of the TCP divided by the window size. Limiting an attack by utilizing this round trip time slows down the transmission rate significantly.
The 3rd approach is to take advantage of the connection limits of web browsers, typically around 256 connections. By maintaining this set number of connections and then by exceeding it, we can make sure that at least one connection is closed when desired in order to trigger TCP resets. This technique avoids the slowness of the 2nd approach.
Direct Attacks
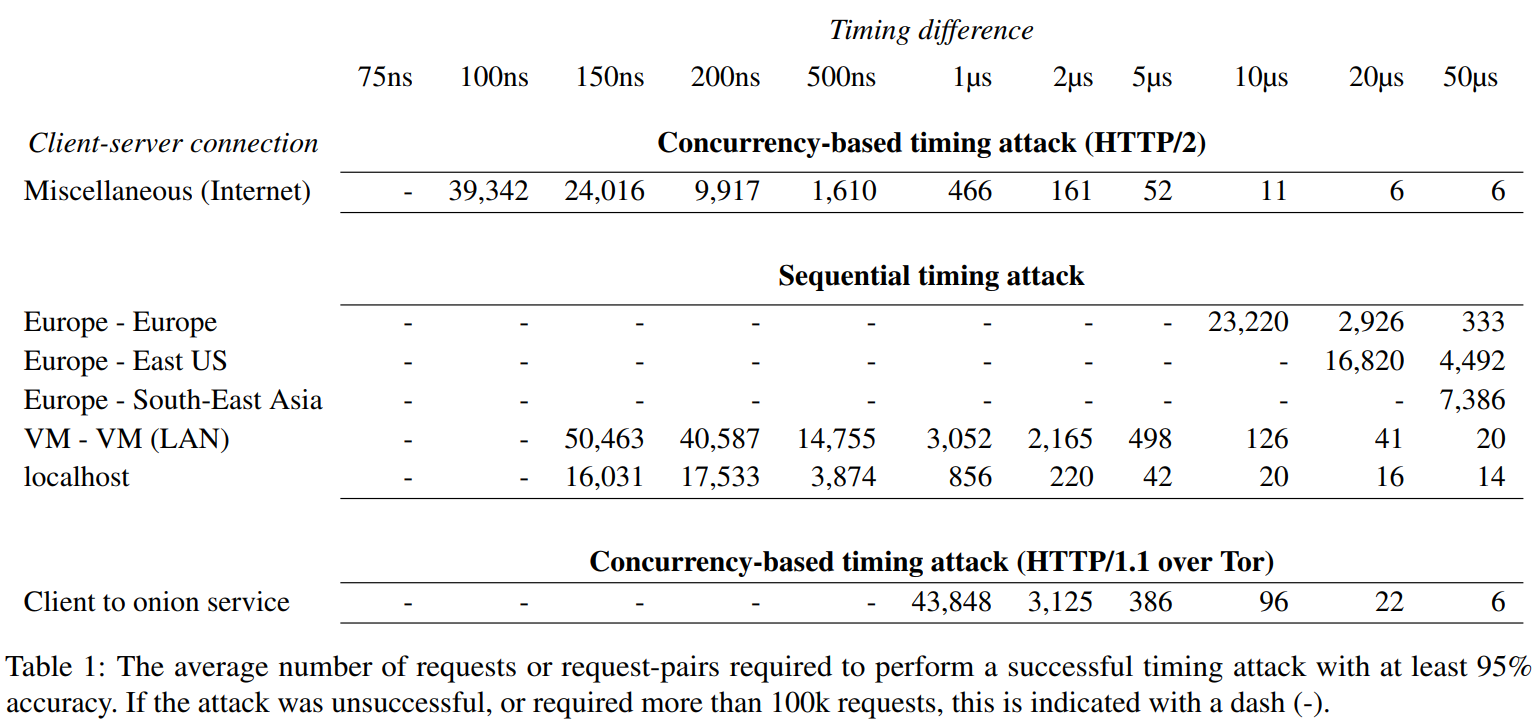
To evaluate the effectiveness of this technique of encapsulating packets to create concurrency-based timing attacks, a number of attacks were performed on simulated targets. Due to jitter in all measurements taken, a number of requests were needed to successfully differentiate timing differences between 2 different types of requests. Successfully measuring the difference between 2 different timings with statistical significance requires a larger number requests when the timing difference is small and when the random jitter caused by random network delays is fairly large.
As seen above, when measuring moderately sized timing differences such as 50 ms, these concurrency based attacks were able to extract significant information in only 6 packets when normally hundreds or thousands of packets were required when using traditional timing attacks. Measuring concurrency based timing attacks using HTTP/2 was successful at measuring timing distances as small as 100 ns, better than traditional sequential timing attacks could achieve even when dealing with local area networks, or even the localhost. Traditional sequential timing attacks require several magnitudes of orders additional requests to achieve significant results. For example, checking for a 20 ms difference in timing on a Web server, a continent away requires only 6 requests using this new concurrency based attack over HTTP/2, but requires 16,840 requests using traditional sequential timing attacks. Smaller timing differences to distant targets are simply impossible using traditional timing attack methods, but work quite well with this new method.
Tor Onion Services
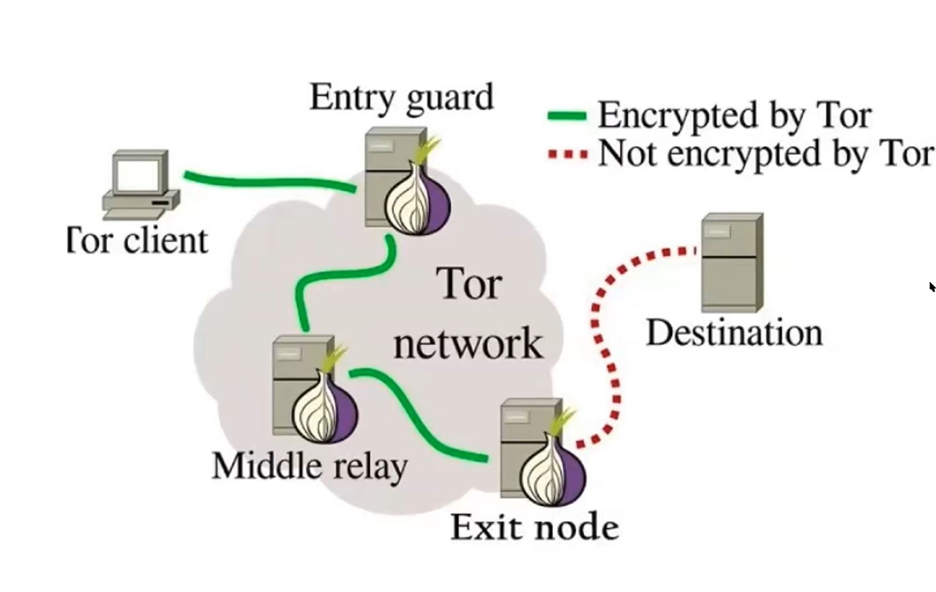
The Tor network encapsulates multiple requests into a single “Tor Cell” and then encrypts this cell for every jump inside the network, but then unencrypted for the final jump between the exit node of the Tor network and the final destination. This also allows concurrency attacks to be performed against onion services that only support HTTP/1.1. Since this is the basic practice already described with Nagle’s algorithm, the same procedure can be followed. Since the internal Tor network has very high latency, buffering needs to take place at the exit node, not the local machine.
To accomplish this, first a huge request is sent through the exit node, followed by 2 smaller requests. The huge request clears the buffer and then the 2 smaller requests will be sent by the exit node combined within the same TCP packet.
Wi-Fi Attacks
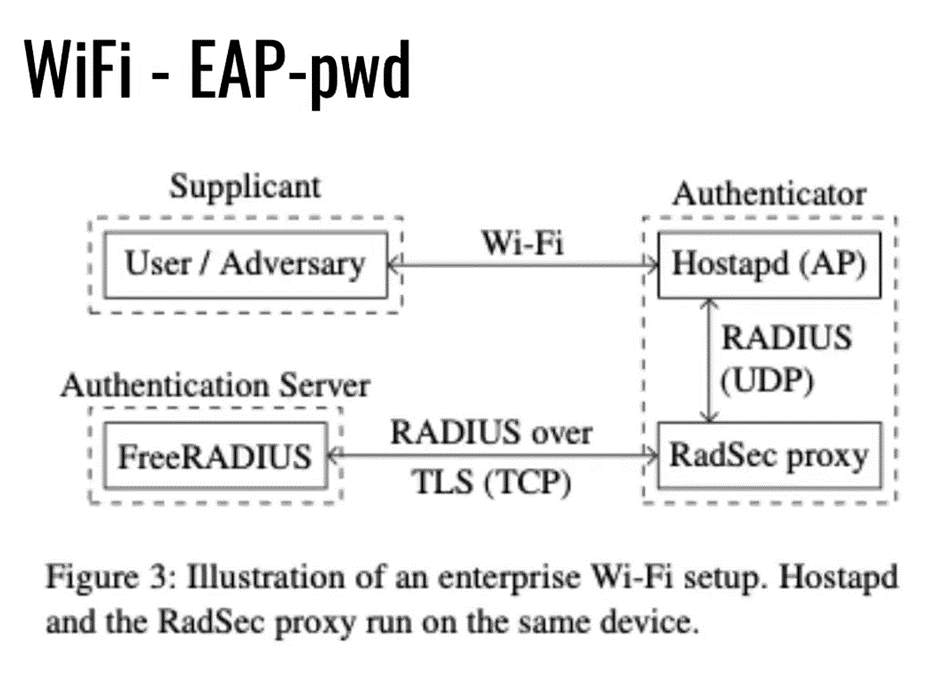
A similar approach can also be used for Wi-Fi password attacks. In a typical enterprise system, a request is first sent over a slow and unreliable Wi-Fi medium, and then passed to an authenticator that packages up the request into a TCP packet and passes the request to an authorization server.
The authentication process uses an algorithm known as Hash to Curve which is vulnerable to a concurrency based timing attack, but not vulnerable to a traditional sequential timing attack due to the latency inherent in Wi-Fi. Hash to Curve takes data from the PWD ID request, hashes it, and then checks to see if the hashed point is on the elliptical curve. If it is not, it is rehashed repeatedly until it is, and then returned. Wireless systems also implement a Fast Initial Link Setup (FILS) that is used for quick reauthorization. If you leave the network and come back, dending this request can quickly re-authenticate without running to the entire original process.
The goal is to trigger two concurrent hash-to-curve calculations because the performance of this algorithm varies, therefore leaving it vulnerable to timing attacks. To do this, an attacker creates a Wi-Fi frame containing 2 PWD-IDs. The authenticator then encapsulates this into a single TCP packet.
One challenge that was encountered was that there are 2 different methods used to aggregate packets. The first is A-MSDU, Aggregate Mac Service Data Unit, meaning that data in each Wi-Fi frame is unique by both sender and receiver. The other method is A-MPDU, Aggregate MAC Protocol Data Unit, meaning that data is only unique for the Receiver only. Only the A-MPDU protocol will allow a spoofed wifi frame to be sent holding data from two different sources going to the same destination.
As long as the 2nd protocol is in use, a proposed attack will pretend to be two different clients and combine their PWD-ID requests containing Wi-Fi passwords into a single Wi-Fi frame. A 3rd client is faked initiating a FILS request (with a fake reauth with the goal of filling the buffer) Because sending two PWD-ID frames with different IDs is not a valid operation within one Wifi frame, the researchers modified an Atheros chip firmware in order to do this. The receive order of the PWD-Commit responses reveals which request took less time.
Running 5000 concurrent requests allowed them to create a histogram of the number of iterations in H2C per password. This signature of “number of iterations per password” is then used to identify passwords. Because this is a very fast process, the authors were able to attack the Rock-you password list using a dictionary attack using a standard video card, at a rate of 2.49*10^9 passwords per second checked.
Limitations
These new techniques allow us to exploit timing attacks in ways previously thought impossible. These implementations are always faster than traditional timing attacks, and often more accurate as well. Web timing attacks over HTTP/2 can be performed about as well as attacks run on a local machine.
Prerequisites for a successful attack include the requirement of simultaneous arrival. There must be a technique that will force two requests to arrive in the same TCP packet. In addition, once packets arrive, they must be executed concurrently. In the protocol itself, there must be support for either multiplexing, or multiple connections will need to be made. Finally, the actual response order must infer some sort of secret information to the attacker.
Other limitations of this method include the fact that our timing information is relative. This is not a problem if time is a rough approximation for the number of results. If we only have an order, then a baseline needs to be found in order to help us interpret our results.
Multistep handshaking protocols and protocols that depend on the outcome of the previous block are impossible to attack using his technique, as they prevent concurrency in the protocol from being exploited. As seen in a few cases, sometimes encapsulating multiple requests in a single packet at a different layer in the protocol will circumvent these limitations.
Defenses
The theoretical defense of forcing everything to execute in constant time will always prevent timing attacks, including concurrent ones. A more realistic strategy is to add random delays to incoming requests. An even more realistic strategy is to add random delays to incoming requests that could be transported together. This unfortunately includes 90% of all HTTP/2 traffic as determined by simulation of real-world browsing. If you only look at padding per endpoint and only pad static content, this drops to a somewhat more realistic 20%.
Another approach to prevent these attacks would be to disable Nagle’s algorithm, or alternatively pad all requests so they cannot be combined with any other requests. It is also possible for a web browser to prevent this information from leaking, but would similarly require substantial overhead.
Discussions
The scientific nugget the paper contributed instilled an almost magical feeling of wonder, which is reminiscent of the scientific prophecies offered by the Mayhem paper and the theoretical papers from the 70s and before. Whereas Kanak shared his own nugget of wisdom: stating, “computers were fake in the 70s.”
The paper detailed a new class of timing attacks that use multi-request encapsulation and order evaluation, which leverages processing parallelism to overcome the random timing delays introduced by network transmission. The richest scientific nugget multi-request encapsulation will likely result in many powerful derivative works over the years to come.
With that said, the paper missed an opportunity by not including a rigorous analysis of their technique. In such an analysis, the paper should have provided a better framework for discussing and analyzing their work by defining and describing the general technique and then applying the general technique to experiments and their results. Such an analysis would have made it easier for the reader to see the paper’s roadmap and the common themes that linked different evaluations together and provided a framework for future discussions. For example, some readers felt like the broad differences between the HTTP/2 and WiFi experiments made for two different papers. However, with some discussion of our own, we found the experiments were meant to show the power and adaptability of the undefined multi-request encapsulation technique and not specific attacks on each of the protocols. Thus, without explicitly defining the concepts it is likely many readers of the paper will miss the most significant scientific contribution the research uncovered, which will hinder future discussions between researchers on this class of attack and potentially slow its adoption.
Nevertheless, this is still a great scientific contribution that provides an amazing net positive to the research community.
Future Directions, Questions, Thoughts
As with many new technologies, HTTP/2 is intended to enable the use of concurrency to speed up HTTP responses; however, it also introduces a whole new attack vector. How widely used is HTTP/2? Can you analyze a server and see if it’s vulnerable to this type of attack. I.e., could postgres, in certain configs, farm out queries concurrently How many programs that are concurrent that have a handler can this be applied to? For example: Can you carefully control when a fd leaks parallel flushes? In a program that uses libc and fprintf is there some sort of buffering that can be exploited to cause the compaction of requests Can we create buffer bloat such that it introduces a vulnerability? Can the technique be used to remove local latency in binaries? Could triggering concurrent requests on different cores be faster than possible context switching on localhost? Would it be possible to use the technique on websites to figure out a user’s password even though any well-respected crypto lib will make sure there aren’t timing attacks that are possible.
