Paper Info
- Paper Name: Symbolic execution with SymCC: Don’t interpret, compile!
- Conference: USENIX Security ‘20
- Author List: Sebastian Poeplau and Aurélien Francillon
- Link to Paper: here
- Team: Team Fable
- Food: Pairs well with intermittent fasting
Symbolic execution with SymCC: Don’t interpret, compile!
Introduction
To improve symbolic execution’s performance, this paper proposes compilation-based symbolic execution: SYMCC, an LLVM-based C and C++ compiler that builds concolic execution. SYMCC takes the unmodified LLVM bitcode of a program under test and compiles symbolic execution capabilities into the binary. Specifically, at each branch point in the program, the “symbolized” binary will generate an input that deviates from the current execution path.
It can be used in practical by developers by replacing clang/clang++ compilers, and can support other languages with little efforts.
The paper compares SYMCC with KLEE and QYSM, results show that SYMCC performs better than state-of-the-art implementations by orders of magnitude. Also, in real-world software, SYMCC shows better coverage and found two vulnerabilities in OpenJPEG with CVE id.
Background
Symbolic execution
While a program is under symbolic execution, the system produces symbolic expressions that can be reasoned to represent the program’s computation, which allows us to, for example, generate new program inputs that trigger a certain security vulnerability. Typically, its implementations use an SMT solver, possibly enhanced by pre-processing techniques, such as KLEE’s caching mechanisms and QYSM’s removing irrelevant information in queries.
Some implementations of symbolic execution execute the target program one single time first with concrete input, and generate new inputs based on the previous. This approach, referred to as concolic execution, is followed by SAGE, Driller and QSYM. On the other hand, several other implementations focus on manage multiple execution path of the program. Typically, they fork the execution at branch points, with a scheduler that prioritizes them according to some search strategy. For example, KLEE, Mayhem and angr follow this approach.
SYMCC follows the concolic approach since it provides higher execution speeds and simpler implementation.
IR-based symbolic execution
A common way of implementing symbolic execution is by means of an intermediate representation (IR). IR-based symbolic execution first needs to transform the program under analysis into IR. KLEE, for example, works on LLVM bitcode and uses the clang compiler to generate it from source code; S2E also interprets LLVM bitcode but generates it dynamically from QEMU’s internal program representation, translating each basic block as it is encountered during execution; angr transforms machine code to VEX, the IR of the Valgrind framework.
In general, IR provides higher level description of the program and is easier to implement a symbolic interpreter than for machine code directly.
IR-less symbolic execution
In the IR-based approach, interpreting IR is much slower than native execution of the corresponding binary, especially in the absence of symbolic data. Triton and QYSM follow another approach: instead of translating the program under test to IR and then interpreting it, they execute the unmodified machine code and instrument it at run time. They both control the target program’s execution with Intel Pin.
The main advantage and original goal of the IR-less approach is speed. Run-time instrumentation still introduces overhead, but tracing native execution while inserting bits of code is much faster than interpreting IR. However, building directly on machine code has considerable downsides due to the much larger instruction set and CPU dependence.
Compilation-based symbolic execution
Overview
The high-level goal of compilation-based symbolic execution is to accelerate the execution part of symbolic execution by compiling symbolic handling of computations into the target program.
To get an overview of how SYMCC works, consider the following function in LLVM IR:
1
2
3
4
5
6
define i32 @is_double (i32, i32) {
%3 = shl nsw i32 %1, 1
%4 = icmp eq i32 %3, %0
%5 = zext i1 %4 to i32
ret i32 %5
}
It takes two integers and returns 1 if the first integer equals the double of the second, and 0 otherwise.
In order to capture this computation symbolically, compiler-based symbolic execution would transform this function to the following instrumentation code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
define i32 @is_double (i32, i32) {
;symbolic computation
%3 = call i8* @_sym_get_parameter_expression(i8 0)
%4 = call i8* @_sym_get_parameter_expression(i8 1)
%5 = call i8* @_sym_build_integer(i64 1)
%6 = call i8* @_sym_build_shift_left(i8*%4 , i8*%5)
%7 = call i8* @_sym_build_equal(i8*%6, i8*%3)
%8 = call i8* @_sym_build_bool_to_bits(i8*%7)
;concrete computation
%9 = shl nsw i32 %1, 1
%10 = icmp eq i32 %9, %0
%11 = zext i1 %10 to i32
call void @_sym_set_return_expression(i8*%8)
ret i32 %11
}
The inserted code calls out to the run-time support library, loaded in the same process, which creates symbolic expressions and eventually passes them to the symbolic backend in order to generate new program inputs.
Support library
To implement these capabilities, SYMCC bundles the symbolic backend into a library that is used by the target program. The library exposes entry points into the symbolic backend to be called from the instrumented target, such as functions to build symbolic expressions and to inform the backend about conditional jumps.
Symbolic handlers
The core of the compile-time transformation is the insertion of calls to handle symbolic computations. The compiler walks over the entire program and inserts calls to the symbolic backend for each computation. Specifically, the compiler inserts code to obtain symbolic expressions for related operands between computation instructions, to build the resulting “equals” expression and to associate it with the variable receiving the result.
The code is generated at compile time and embedded into the binary. This process replaces a lot of the symbolic handling that conventional symbolic execution engines have to perform at run time. Moreover, the inserted handling becomes an integral part of the target program, so it is subject to the usual CPU optimizations like caching and branch prediction.
Concreteness checks
Although compiler-based approach reduce much overhead, it still ultimately invokes the symbolic backend and may put load on the SMT solver. However, involving the symbolic backend is only necessary when a computation receives symbolic inputs. There is no need to inform the backend of fully concrete computations. To mitigate this issue, SYMCC has two stages to identify concrete data:
- Compile time: Compile-time constants, such as offsets into data structures, magic constants, or default return values can never become symbolic at run time.
- Run time: Checking at run time and preventing invocation of the symbolic backend dynamically if all inputs of a computation are concrete.
Consequently, SYMCC library omit calls if data is known to be constant at compile time, and insert run-time checks to limit backend calls to situations where at least one input of a computation is symbolic.
Implementation
Evaluation
Benchmarks
Evaluation of SYMCC was performed via comparison with QSYM and KLEE on the DARPA Cyber Grand Challenge (CGC) binaries.
Each CGC binary has a known vulnerability, making it an ideal test corpus. This set of binaries was also selected because it was used in the QSYM evaluation. Patching KLEE was necessary to enable it to analyze the CGC programs. Six CGC programs were excluded because they utilized communication between multiple components or presented varied behavior across compilers. The CGC programs also use a custom standard library implementation. This is critical as SYMCC does not symbolically execute the C standard library. This custom standard library can be symbolically compiled.
Three benchmark evaluations were performed, evaluating:
- Execution performance inside the symbolic execution tool without any symbolic data
- Execution performance with symbolic inputs
- Code coverage when used with concolic execution
KLEE was selected for evaluation because it interprets bitcode, oppose to SYMCC’s compilation approach. QSYM was selected because SYMCC reuses the QSYM backend, allowing for a comparison of compiling vs interpretation techniques. S2E and Driller were not included in the evaluation. S2E is based on KLEE, and preliminary evaluations showed the two yielded similar results. Driller, which utilized angr for symbolic execution, was discarded due angr’s python implementation resulting in a comparatively slower execution time.
Pure execution time was measured by executing the CGC programs with the known proof of vulnerability (PoV) as input. No data was marked as symbolic, as the goal was to measure pure concrete execution time. Results are shown below.
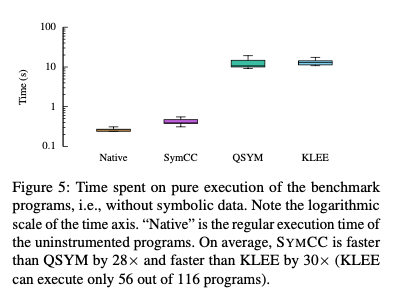
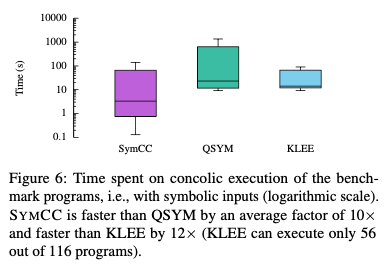
The second evaluation performed concolic execution on the GCG programs with the PoV as input. The input data was marked as symbolic to enable test case generation. KLEE’s forking and scheduling components were modified to avoid bias. The authors note that some additional overhead work was still performed by KLEE that would negatively impact performance.
Coverage scores were also generated from this experiment comparing SYMCC with KLEE and QSYM directly.
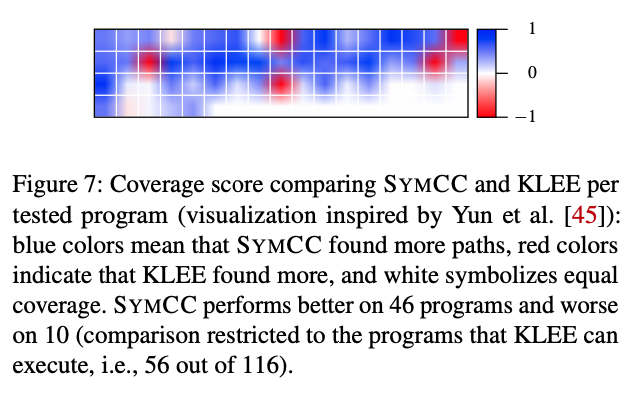
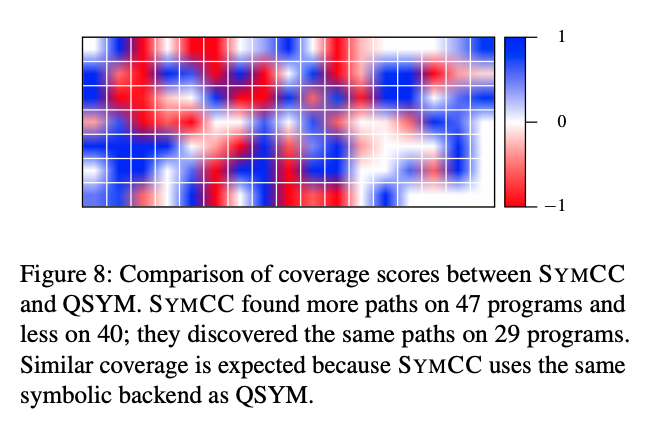
The authors node that this method of presenting code coverage suffers from a distinct flaw. If two systems predominantly discover the same paths, a small number of unique paths become overrepresented. In effect, this masks the total number of paths found by both systems. For the authors’ purposes however, it is effective in displaying the amount of similarity of paths found.
Real-world software
An additional comparison using real-world software was also performed. OpenJPEG, libarchive, and tcpdump binaries were selected for this experiment. KLEE was not used in this comparison due to unsupported instructions in the target programs. Concolic execution was performed by running an AFL master instance, a secondary AFL instance, and on instance of QSYM or SYMCC. Test cases generated from symbolic execution were passed to the fuzzers.
Each experiment ran for a total of 24 hours. The experiment was repeated thirty times. Code coverage and time spent performing symbolic execution were measured.
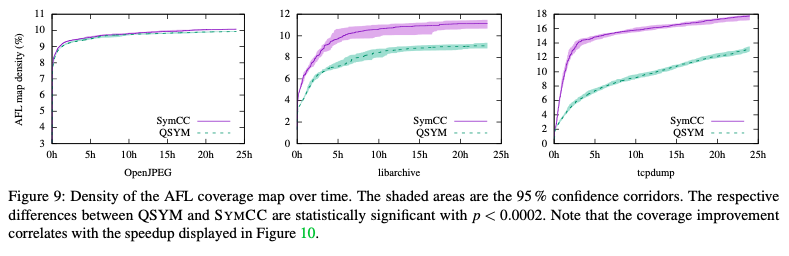
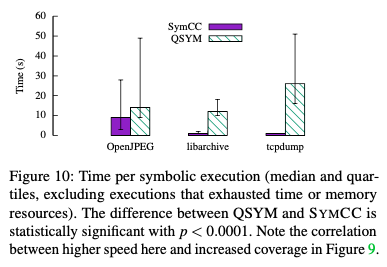
As a result of the experiment, SYMCC discovered two CVEs in OpenJPEG. The authors conclude that SYMCC performance is better than current state-of-the art systems in both benchmark tests and real-world software.
Discussion
The Argument on IR
In the opening remarks of this paper, the authors spent some time framing their paper as a compilation versus intermediate representation approach for symbolic execution:
We propose compilation-based symbolic execution, a technique that provides significantly higher performance than current approaches while maintaining low complexity.
We thought this emphasis on the paper calling for compilation over intermediate representation was far too push for the claims this paper had. This mainly spawned from our discussion on the evaluation against KLEE which had been nearly 10 years old at this point. Considering this, it poses the question whether KLEE performed badly because it’s approach was primitive, or because it was full of age induced bugs.
The Consensus
Overall we really enjoyed this paper. We thought the evaluation was very logical and fundamental claims that were supported by the evidence. We had very little discussion on other parts of this paper aside from the assumptions that were made inside compilation
Some member of this discussion asked whether this idea was truly novel compared to something like QSYM which had done JIT compilation, but ultimately we thought this was an improvement to the state of symbolic execution.
Our only other gripe is that we felt as though this end result software is a very single project type of publishing – meaning we thought that in the future this code will not be built upon. We think this because the code did not show good ways to be extended (having relation to the compilation for language over IR).