Paper Info
- Paper Name: An Observational Investigation of Reverse Engineers’ Processes
- Conference: USENIX Security ‘20
- Author List: Daniel Votipka, Seth Rabin, Kristopher Micinski, Michelle L. Mazurek
- Link to Paper: here
- Food: Pairs well with soft pretzels
Introduction
Towards a better understanding of reverse engineers’ processes, this paper presents a semi-structured, observational interview study of reverse engineers, with the goal of producing insights for improving interaction design for reverse engineering tools.
In particular, they set out to answer the following research questions:
RQ1. What high-level process do REs follow when examining a new program?
RQ2. What technical approaches (i.e., manual and automated analyses) do REs use?
RQ3. How does the RE process align with traditional program comprehension? How does it differ?
They used an exploratory qualitative approach based on prior work in expert decision-making and program comprehension. To this end, they conducted a 16-participant observation study. For participants, they were asked to recreate RE experience while were observed to track the process of decision making, hypotheses formulated, and beacons(recognizable patterns) identified.
In results, they modeled the RE process to three phases:
Overview (of the program’s functionality)
- Sub-component scanning(specific useful components)
- Focused experimentation(execution/debugging or in-depth static analysis)
Based on these results, the paper suggest five guidelines in the end for designing RE tools.
Background
Naturalistic Decision-Making
NDM research focuses on these decision-making processes and uses interview techniques designed to highlight critical decisions, namely the Critical Decision Method, which has participants walk through specific notable experiences while the interviewer records and asks probing follow-up question. They apply the Critical Decision Method to guide the investigation.
Program Comprehension
Program comprehension research investigates how developers maintain, modify, and debug unfamiliar code similar problems to RE. Programmers’ hypotheses are based on beacons recognized when scanning through the program. To evaluate their hypotheses, developers either mentally simulate the program by reading it line by line, execute it using targeted test cases, or search for other beacons that contradict their hypotheses. They anticipated that REs might exhibit similar behaviors, so they build on this prior work by focusing on hypotheses, beacons, and simulation methods during interviews. At the same time the paper also hypothesized some process divergence, like RE’s targets are usually obfuscated code and raw binaries, and focusing on exploiting flaws.
Method
The paper employ a semi-structured, observation-based interview protocol to study RE experts’ process.
They implemented a modified version of the Critical Decision Method, which is intended to reveal expert knowledge by inquiring about specific cases of interest. They asked participants to choose an interesting program they recently reverse engineered, and had them recall and demonstrate the process they used. Each observation was divided into the two parts: program background and RE process.
Program background: describe the program, includes functionality, size and RE tools they used.
Reverse engineering process: program-specific RE goals and questions, and recreating their process with sharing screen.
- Decisions: including deciding whether to delve deeper into a specific function or which simulation method to apply to validate a new hypothesis
Hypothesis: why they think the hypothesis might be true and how they tested it
- Simulation methods: to evaluate any tools like debuggers to discuss their effectiveness
- Beacons: how REs perform pattern matching, and identify potentially common beacons of importance
Data analysis
After organize interview data into an initial codebook, they develop a theoretical model by: first, grouping identified codes into three categories: Overview, Sub-component Scanning, and Focused Experimentation. Then they performed an axial coding to determine relationships between and within each phase and trends across the three phases, and derived a theory of REs’ high-level processes and specific technical approaches.
Participants
They recruited interview participants from online forums, vulnerability discovery organizations, and relevant conferences.

Reverse Engineering Process Model
Based upon the actions of participants, the reverse engineering was defined as a three phase process:
- Overview
- Sub-component scanning
- Focused experimentation
First, a high-level understanding of the program’s This information is used to determine which parts of the program are of particular interest and warrant deeper exploration. This focused analysis leads to specific questions and hypothesis generation. Lastly, these hypothesis are directly tested to provide greater insight into program behavior. This information is then used to investigate sub-components further.
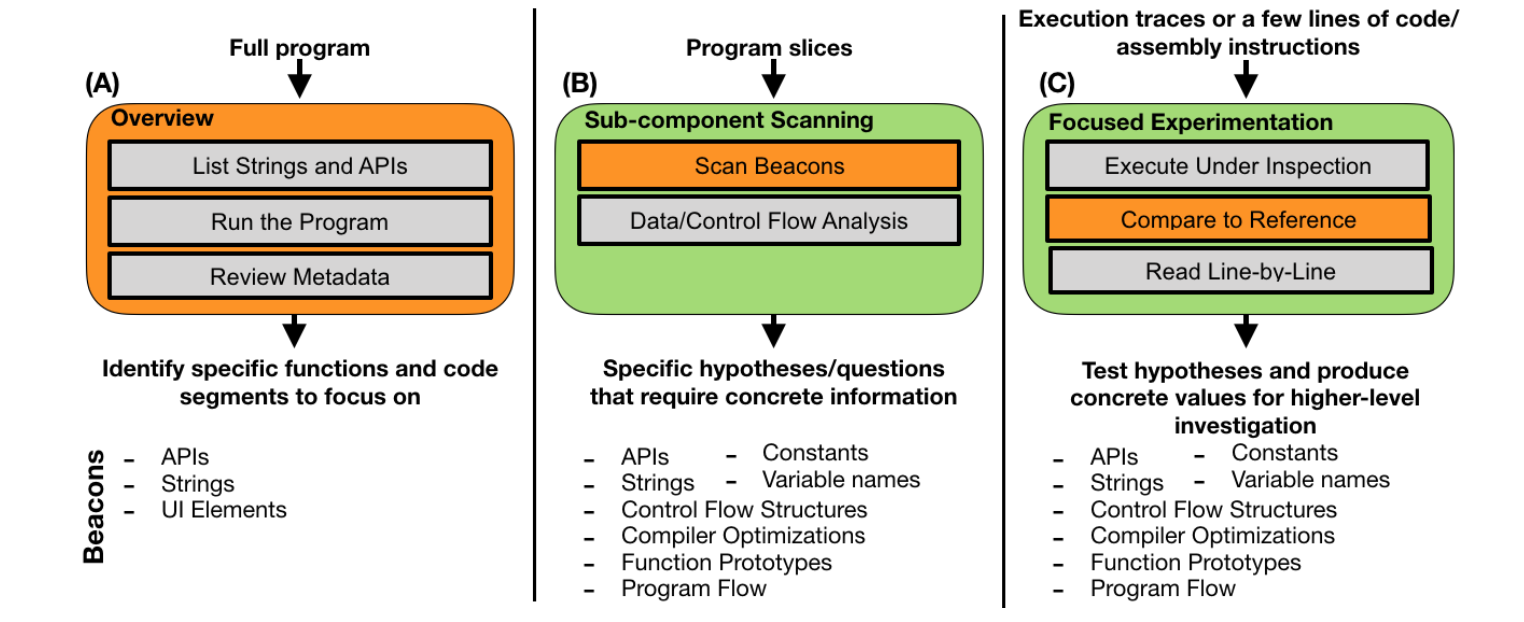
Overview
During the overview phase, reverse engineers use a their high-level knowledge, familiarity with the program, and prior experience with similar programs to reason about the program.
Identify the strings and APIs used - Strings and API calls can immediate provide information about program behavior. Combining these keywords with a high-level mental model of likely program structure allows reverse engineers to identify where in the binary expected activities are performed.
run the program and observe its behavior - Similarly, simply running the program can provide additional context to strings or other visible program elements. Even the lack of a particular value or element can guide the reverse engineer to deduce high-level design decisions about the program.
Review program metadata - Program metadata, such as traces, libraries loaded, or function size offer additional insight into the program.
Malware analysts perform overview after unpacking - Malware is often obfuscated (packed) until execution time. In these instances, malware analysts must unpack the binary. After doing so, the other overview steps are the same.
Overview is unique to RE - The authors note this overview step is unique to reverse engineering. In other scenarios, such as debugging, the engineer is likely to already be familiar with the program and have access to additional information such as documentation,
Sub-component Scanning
Sub-component scanning begins after the high-level program behavior has been established. The framing of questions tend to shift from asking what a section of code does to how does it perform this functionality. This action is still a somewhat high-level task because reverse engineers are wary of spending too much time answering a specific questions that may not necessarily be fruitful.
Scan for many beacons - Scanning specific sections of code for known API calls, constants, and variable names allows functionality to be inferred without requiring complete understanding. Combining these beacons with experience, reverse engineers can quickly identify common patterns in control-flow or naming conventions identifying functionality found in similar programs.
Focused on specific data-flow and control-flow paths - Reverse engineers often focus on a single data-flow to understand how data is passed from one function to the next. This process is used to determine if a potentially vulnerable action can be realized in the program based upon how the variable is created and mutated earlier in the program.
The diversity of beacons represents a second difference from program comprehension - Comparing these activities with developers, reverse engineers often rely on less obvious beacons such as control flow and program flow to gain additional understanding.
Focused Experimentation
After gleaning as much information as possible from the first two steps, reverse engineers shift to answering specific questions to support or refine their understanding of the program.
Execute the program - Many hypothesis can be confirmed by running the program under specific circumstances and observing if an expected behavior occurs. This can include checking variable values at specific points of execution such as observing if malformed input reaches a particular location in the program in a debugger, but often simply observing changes in program behavior can serve as confirmation. Fuzzing is often used for this purpose, but in the reversing context, this is performed manually to answer specific questions rather than through the use of an automated tool that performs random input mutations.
Compare to another implementation - When a reverse engineer has a high-level understanding of a function, it may be easier to re-implement the behavior in a high-level language and compare function output. Similarly, program functionality can be confirmed by comparing output with a reference implementation in the case of open-source software.
Read line-by-line only for simple code or when execution is difficult - When other options cannot help, reverse engineers will manually reading small sections of code line by line. This can occur when a program may take additional time to run correctly, or a very specific implementation detail needs to be understood. Ideally, this step is performed manually leveraging the reverse engineers knowledge, but often times tools such as symbolic execution are utilized to assist in more complex scenarios.
Beacons are still noticed and can provide shortcuts - Although this step focuses on answering a very narrow and specific question, additional beacons can be found during this step that may immediately invalidate or confirm a hypothesis. This often provides sufficient information to abandon further investigation and explore another aspect of the program.
Simulation methods mostly overlap with program comprehension - Many of these techniques are found in program comprehension literature. The use of reference implementations for comparison is unique to reverse engineering. This is attributed to the reduced information available to the reverse engineer.
Results: Trends Across Phases
The authors also noted several trends that spanned the different phases; these comprised both answers to initial research questions that simply weren’t phase-specific as well as further observations.
The first trend was beginning with static analysis and finishing with dynamic analysis. The initial two phases primarily focused on static analysis before transitioning to dynamic techniques for the focused experimentation phase. Of note was the potential for this switch from static to dynamic analysis to disrupt work, as information needed to be manually transferred over. Using both static and dynamic tools side-by-side was one approach to alleviating this issue.
The next trend was the tendency for experience and learned strategy to guide the first two phases. At the beginning, there isn’t a defined scope of exploration, and so prior experience is used to bridge this gap. In a familiar area, one may have some standard process; one participant noted a prioritized list of different APIs to check when dealing with iPhone vulnerabilities. In the absence of this experience, general search strategies take over, such as prioritizing larger functions as probably more interesting. Later, in the second phase, this experience again helped participants form hypotheses based on knowledge of previous vulnerabilities.
Another observed trend was the use of experience to select analysis methods. Some participants would forgo the first phase entirely and begin directly with the main function. Another common observation was knowledge of tool limitations enabling participants to second-guess potentially buggy results; specifically, one participant noted the importance of realizing the Hex-Rays decompiler is buggy rather than trusting its output directly.
Another observed trend dealt with tool selection. The participants’ preferred tools allowed results to be mapped back onto specific lines of code, such as viewing the strings of a binary in IDA rather than using strings. One participant was noted to use a method which did not allow for this (manually mapping back and forth between a symbolic representation and the program itself), but explicitly stated that this was only due to not knowing a tool which could accomplish it in that instance.
Another broad trend was a focus on improving the readability of code. This could involve the use of a decompiler or other methods to improve the usefulness of assembly. Most participants were observed to rename variables, reconstruct data structures, and explicitly take notes as a result of their analysis. One participant specifically called out the case of several manipulations of a single variable as requiring notes to keep track of.
Finally, the last cross-phase trend observed was a tendency to query online resources in order to aid analysis. System and API documentation was widely used, as were third-party breakdowns of the poorly documented aspects. If these approaches failed, some participants searched StackOverflow hoping the issue had been encountered before, or searched for unique constants in the algorithm they were analyzing (e.g. searching the initialization vector for MD5 reveals the algorithm).
Discussion
Meaningful Analysis of Reversing
One of the first topics that our group talked about was the non-grandiose claims that this paper had made on the reverse engineering process. As compared to some of the recent literature in investigating reverse engineering, we felt this paper did an exceedingly good job at making claims that were fully backed by this paper. We felt particularly fond about the generality of the reverse engineering process they described with the earlier used image.
The author throughly investigated the reversing process, and kept the claims general. In addition, the authors even explained their at-first-glance tiny dataset of 16 people – claiming convergence of observed results. Overall, we felt this paper had a meaningful contribution to the scientific community that will help the future of research in this area. The introduction of “beacons,” though simple, was a valuable explanation of some important concepts in reverse engineering.
Usefulness For Beginners
On the note of explaining the reverse engineering process, there was some discussion about the usefulness of this paper for beginners in reverse engineering. To any individual who has done some reverse engineering, the concepts of this paper may feel trivial, but we felt that the description of the reversing process can be helpful to a software engineer that has never reversed software before.
Some mentioned that there are various gems for beginners in this paper that spans past the earlier mentioned diagram that describes how reversing works. Some of these gems are as simple as the more experienced reverses in the paper looking for commonalities across software – like the example of pinging websites for a malware to detect if it has connection to the Internet.
Others in the group claimed that the usefulness for beginners in this paper could be simply reduced to the single reversing diagram. The claim stemmed from the high level of generality that the reverse engineering process was described in throughout the paper. Most new reverse engineers will only benefit from knowing they should:
- Be looking for beacons across the target
- Not spend too much time on a single section of the code.
These concepts can mostly be parsed from reading a single section of this paper.
The Future of Reverse Engineering Tools
The last discussion that stemmed from this paper was the need for betting tooling in the RE process. Through this paper we had more discussion about the need for a minimal context-switch when reversing. This paper shows how often we need intense context switching of work when we want to static analysis versus dynamic analysis. Currently, there lacks a single tool which provides both good static and dynamic analysis with little switch.
Some of this discussion poured into the reliability of plugins that attempt to bring these features to lite in newer tools.