Paper Info
- Paper Name: The Industrial Age of Hacking
- Conference: USENIX Security ‘20
- Author List: Tim Nosco, Jared Ziegler, Zechariah Clark, Davy Marrero, Todd Finkler, Andrew Barbarello, W. Michael Petullo
- Link to Paper: here
- Food: Pairs well with cupcakes, preferably lemon meringue or s’mores.
Abstract
At the core of this paper is the observation that most bug- and vulnerability-finding is done without specific indication that these are likely to exist. The paper terms this the depth-first approach and proposes a new method of searching for vulnerabilities: breadth-first. Their proposed breadth-first process revolves around the idea of investing minimal human effort early on, just enough to enable automated analysis, and thereby increasing the number of targets that can be investigated. The aim of the process is threefold: the discovery of bugs, the efficient use and coaching of the people involved, and a quantifiable process with incremental progress. The authors claim that this breadth-first search strategy increases the overall effectiveness of teams. Other work has studied these same processes, particularly Votipka, et al., whose vulnerability discovery process is built upon in this paper.
Vulnerability Discovery
The vulnerability discovery process described primarily adds a targeting phase to Votipka, et al.’s process, and this augmented process shown here is described in the following sections.
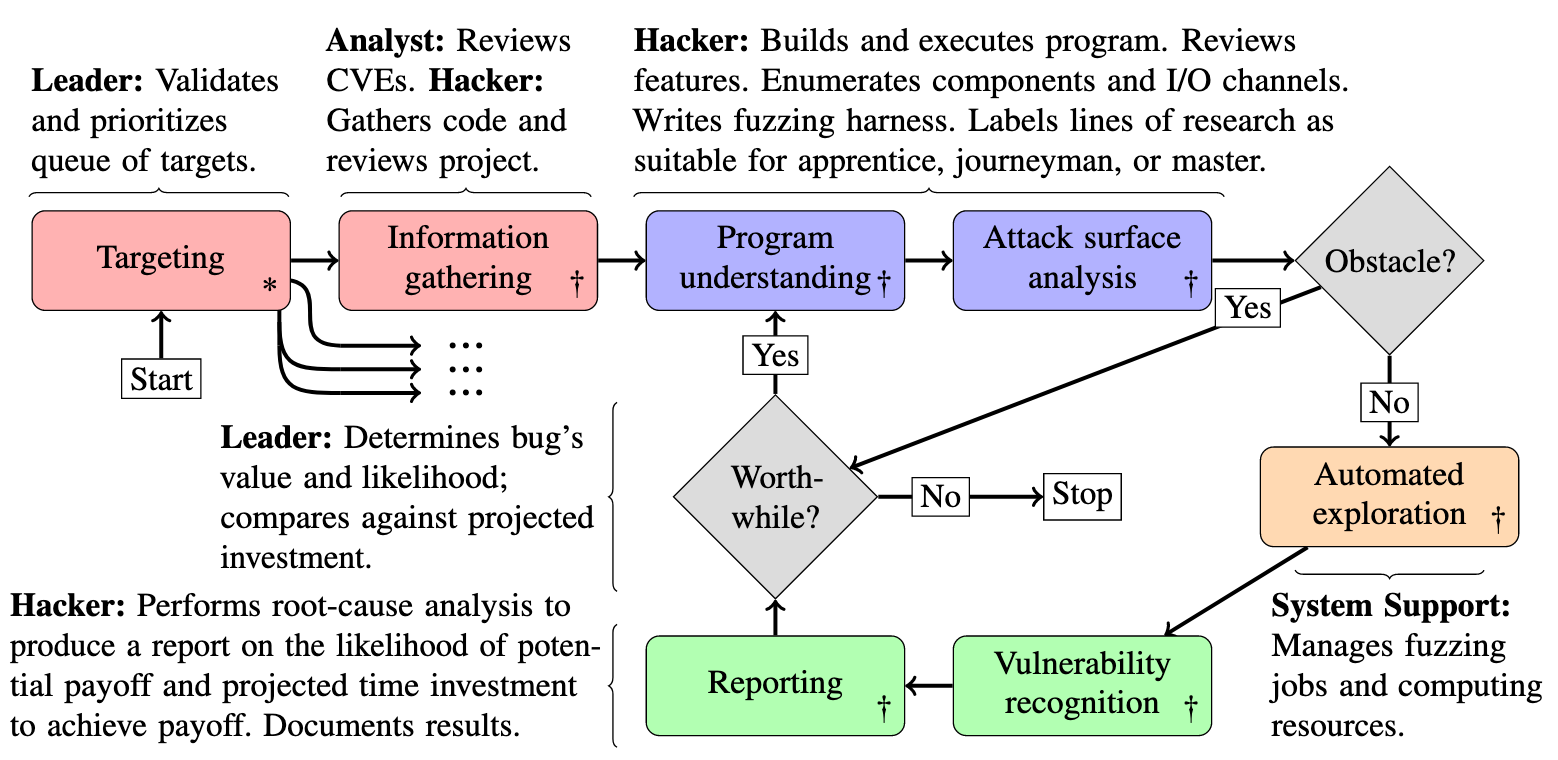
In this paper, bug finders are broken down into three categories comprising the hackers: apprentices, journeymen, and masters. An apprentice is characterized by a reliance on automated analysis tools, such as fuzzers. Journeymen are differentiated from apprentices through their ability to modify programs for easier analysis, whether through source code or binary patching. Masters are in turn differentiated by the ability to alter or create analysis tools. Non-hacker team members include leaders, whose responsibility it is to select targets based on the results of hackers, as well as analysts and support personnel.
Targeting
As mentioned before, it is the addition of targeting to the Votipka process that represents the largest divergence. The goal of targeting is to break systems down into targets which may be individually analyzed later on. Examples given in the paper include a web browser breaking down into distinct targets: networking libraries, the javascript engine, the renderer, etc. In the described process, the targeting phase for a certain system considers existing analysis work, access to source code and bug trackers, and the impact of potential bugs, among other pragmatic factors. The overall model for selecting targets is based on the expected profit of analysis increasing with the likelihood of bugs and the value of such a vulnerability and falling with the expected time and required skill level.
Information Gathering
This is the first step taken by hackers and analysts, with an aim of collecting information needed for later decisions to be made. Information such as the development process of the target, known previous bugs, and any prior analysis are relevant at this stage.
Program Understanding
In this phase, hackers gain knowledge of the design and use of the target. Of particular interest are how the target is commonly deployed, configuration options for more advanced uses, and the overall design of the software itself.
Attack Surface Analysis
At a high level, this phase revolves around coming up with ways to supply inputs to various aspects of the target program. This is the first stage of the process that is highly differentiated by hacker skill level. Prior work in this area has often pointed out that master-level skillsets are often required to begin work; the authors note finding several counterexamples where apprentices and journeymen were able to discover vulnerabilities without requiring the assistance of a master.
Apprentices
Apprentices apply standard automated tools as long as they are useful, and bail out at the first sign of trouble. Their work up to that point is documented, and the apprentice moves on to a new target.
Journeymen
Journeyman utilize the documentation from prior work by apprentices to skip ahead and utilize their skill set to work around the issues encountered by the apprentices.
Masters
Masters likewise utilize documentation from prior apprentice and journeyman work to skip directly the aspects requiring their skills, such as those requiring changes to existing analysis software or new forms of analysis entirely.
Automated Exploration
Since the previous phase involves learning to manipulate program inputs, this phase is free to leverage that knowledge and any fuzzing harnesses produced. Predictably, fuzzing is the most common manifestation of this stage.
Vulnerability Recognition
Bugs that are discovered in the previous stage must now be analyzed to determine if they represent a vulnerability. Certain bugs may lead to more obvious vulnerabilities less-skilled hackers can directly exploit, or they may require the target being handed off to a more skilled hacker.
Reporting
In this phase, the hacker who actually exploits a vulnerability prepares a report with a goal of enabling the developers to fix the bug.
Depth-first
In a depth-first targeting strategy, targets are selected based on the predicted impact of discovering a bug. Targets which are selected are audited by the team entirely, and each target is focused on for a considerable period of time. The authors note the prior effectiveness of this approach when dealing with large projects requiring a period of familiarization, specifically referring to bugs found in the Safari browser by Google’s Project Zero.
The primary pitfall of this strategy is stated to be inefficiency at utilizing individuals of varying skill; anyone might find a bug that an apprentice could exploit, but after a certain point, these apprentice-level issues will be exhausted. In this case, apprentices and occasionally journeymen may find themselves unable to meaningfully contribute to the analysis of any of the remaining targets.
Breadth-first
At the core of the proposed breadth-first targeting strategy is an increase in the number of targets. Given enough potential targets, lower-skilled hackers are free to jump to a new target as soon as it becomes clear that they cannot make further progress on their current target. These abandoned targets are then queued to be handled by available journeymen, and likewise by masters if necessary. To increase breadth even further, the described process stops all work on a target during automated analysis, further increasing the total number of targets that may be analyzed. The authors provide several ideas for increasing the number of targets, including breaking down targets into multiple smaller targets and transitively considering the dependencies of a target. Another benefit pointed out by the paper is that a much larger queue of potential targets allows new team members the freedom to select targets compatible with tools they are already familiar with. The process of handing off targets to more-skilled hackers also provides a feedback mechanism for those attempting to improve their skills: a more skilled hacker will pick up where they left off and document their approach to resolving whatever difficulties forced earlier hackers to move on.
Experiment
Subjects
15 subjects are selected from US Cyber Command personnel, with these basic requirements:
- had experience with Linux
- could work with open source projects
- could conduct Internet-based research
- could read/write C programs
and the distribution of the original 15 applicants contained: 8 subjects under 1 year of experience, 2 subjects between 1-2 years, 2 with 4 years, 2 with 5 years, and 1 subject who reported 8 years experience.
Orientation
They provided orientation and skill assessment to 12 subjects during the experiment.
On the first day, they provided introductions of popular fuzzing tool, AFL, combined with a lecture with exercises includes compiling by afl-gcc, fuzzing bzip2 with afl-qemu and Docker.
We administered these skill assessments three times:
immediately after the initial training course,
- at the half-way mark (before the teams exchanged strategies),
- at the end of the experiment.
The aim was to measure the amount of skill our subjects developed during the course of executing each strategy.
The content of assessments consist a set of different five binaries with two goals: create fuzzing harnesses and find bugs, in exactly one hour time.
Targets

They chose OpenWrt packages as benchmark. For groups working with Depth-first strategy, their targets are dropbear and uhttpd. For Breadth-first targets, subjects could choose any one in OpenWrt packages except dropbear and uhttpd.
Note that this strategy of target selection could lead to bias on the number of found bugs, naturally more targets would lead to more bugs. The author argue that: this perceived unfairness is really intuition that Breadth-first is more effective than Depth-first strategy.
work flows & tools

They use Gitlab project/issue to manage teamwork. A project’s status consisted types of open, information gathering, program understanding, exploration, and journeyman, with following working steps:
- start a target by dragging a ticket from open to information gathering
- append to an issue relevant articles, blogs, source repositories, corpora, and other information uncovered during their search
- move an issue from information gathering to program understanding when subjects start to create products in Gitlab repo
- move an issue to the exploration list upon creating working fuzzing harness
- move an issue to the journeymen list if progress becomes too difficult.
The workstations contained tools including: Ghidra, AFL, Honggfuzz, Docker and Mayhem.
Execution
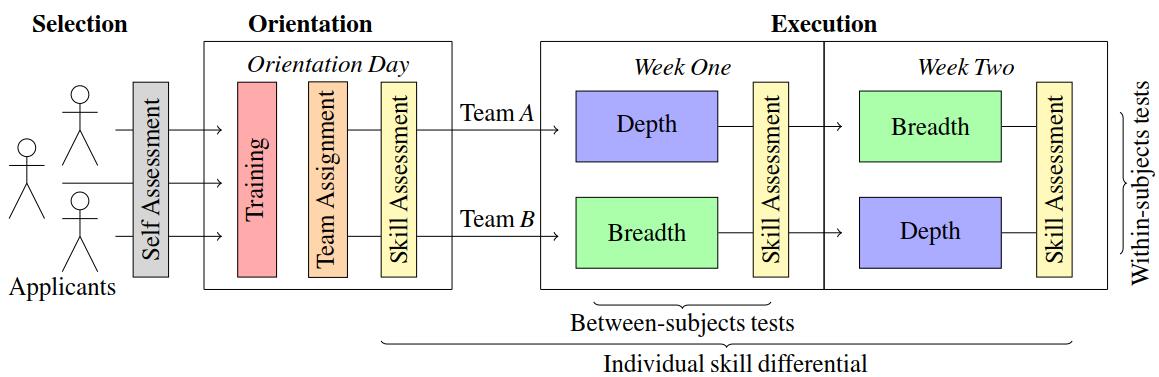
The experiment involved two iterations. During each iteration, each team applied different strategies for one hour, then they exchanged strategies and completed corresponding assessments and surveys.
Results
Surveys
Team members were surveyed hourly on their feelings regarding the use of each process during the experiment. In both weeks of the experiment, surveyed team members using the breadth-first search strategy felt less surprised (MW=0.003), less doubtful (MW=0.004), and spent more time with tools or harnessing (MW=5 X 10-7). At the conclusion of the experiment Team members found depth-first search to be less effective (B=0.019). Likewise, subjects preferred breadth-first search (B=0.03). It was also easier to start (B=2.4 X 10-4) breadth-first search, and it was easier for novices to contribute (B=2.400 X 10-4). However, breadth-first search resulted in members feeling like less of part of a team (B=0.003). The authors note, “We must assume our sample of 12 is ‘large enough’. To balance the number of tests with our small sample, we use an acceptance criteria of 0.020.”.
Number of bugs found
To account for the randomness of fuzzing results, the authors ran each harness created during the experiment in three independent trials for 24 hours in the manner intended by the harness creator. Bugs were de-duplicated via the mechanism described in Mayhem Mann-Whitney was used to test the mean difference in coverage and bug metrics. The cumulative number of unique bugs found in each independent trial is shown below.
| Team | Method | Harnesses | T0 | T1 | T2 |
|---|---|---|---|---|---|
| A | Sd | 8 | 3 | 2 | 3 |
| A | Sb | 42 | 31 | 23 | 40 |
| B | Sb | 61 | 42 | 49 | 40 |
| B | Sd | 12 | 4 | 4 | 4 |
After combining both team’s findings a significant result was found to claim f(Sd) < f(Sb) with p-value 0.002 < 0.02. The breadth-first search strategy not only found more bugs, but found a greater variety of bugs.
Hacking Skill assessment
Subject’s work products were assessed on:
- Number of working harnesses
- Number of bugs found
- Number of bugs reproduced
A working harness was defined as: any harness that found new paths shortly after starting. A bug was defined as: any termination by a signal that may result in a core dump. All measurements were then combined into a single score with each category was given equal weight. A Friedman signed-rank test was used with an acceptance criteria of 0.02. The results were found to not be significant.
| Group | p-value |
|---|---|
| All twelve participants | 0.02024 |
| Group one | 0.10782 |
| Group two | 0.12802 |
Ancillary data
Team member work activities were categorized and binned into hour-long blocks based upon time spent with X11 focus on Firefox for each strategy. No significant difference in work activities were found between depth-first search and breadth-first search based on a Wilcoxon signed-rank test. The Firefox browsing history also did not significantly relate to the strategy the team utilized.
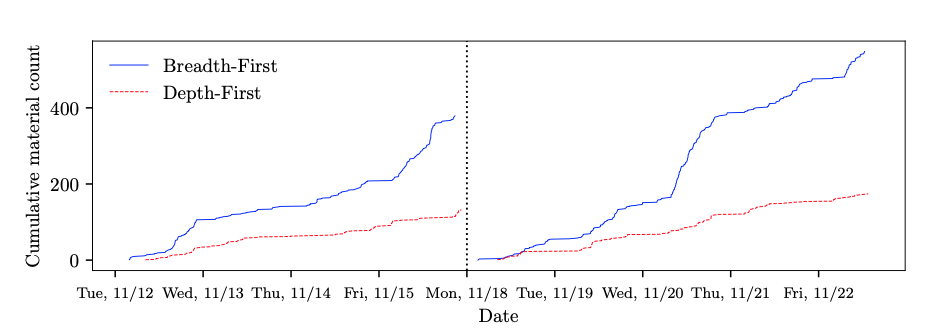
Materials Produced
Both teams produced more materials using breadth-first search over depth-first search.
| Team | Method | Materials |
|---|---|---|
| A | Sd | 151 |
| A | Sb | 588 |
| B | Sd | 177 |
| B | Sb | 387 |
Discussion
Our discussion on this paper went down many paths during the course of meeting. This summarizes the main points that we talked about.
Criticism
The first thing we talked about was that this paper’s evaluation may not represent the real world of vulnerability hunters. In the real world, you don’t search for bugs for only 10 days, and you most certainly don’t DFS for only 5 days. When comparing DFS and BFS in such a short period, of course BFS will win in finding more bugs, but these bugs are often less impactful. The paper does not address this issue in it’s evaluation. Often in the real world you DFS for months on a single target. In some way we felt a comparison of bugs may have been warranted to distinguish the impact of the bugs. This can be seen in the graph above in Materials Produced section.
Continuing on this idea, the authors measure success from teams in terms of bug creates and materials created from these two methods. We feel it was important again to mention that simply because another group created more materials, does not mean the materials were useful. A better method for measure material output would be measure the amount of materials generated that were used by expert level hackers to find bugs. Simply comparing general materials is not a good way of showing if any of the material was useful for research towards discovering a bug.
On a realted matter, we felt that this paper now makes it harder for other papers in the field to discuss results pertaining to hacking in the DFS method. This happens because this paper shows/claims that the BFS methods is a better method for hacking efficiently in a group of hackers, and thus every paper after this will need to address how they beat this paper. If the evaluation in this paper truly was flawed, then papers in the future will find it increasingly difficult to outperform this paper.
Showing that BFS is always better than DFS, with possibly flawed evidence, makes it hard for future papers to go forward.
Measuring Human Utility
One discussion that ensued during the earlier criticism section was the way this paper could have measured success. This paper mostly focuses on bugs and material collection and tries to relate that to finding more vulnerabilities, but we thought that might not be the only thing that is valuable. Human utility could be highly relevant to this paper. In this paper, the periodic surveys shows that participants feel happier and more confident when they work in the BFS methods, and consequentially have more utility due to being happy and less frustrated. This paper could have addressed how working in the BFS method is a powerful way to maximize human utility (or the amount of work each person can output), which may not be directly correlated to the amount of bugs produced. This would hold a gripping argument that when working with many people, DFS decreases the amount of human utility.
Contribution to the Community
Overall, we felt this paper ushered in a novel idea about measuring the productiveness of bug hunting and how different methods may relate to the new methods of looking for bugs. This was indeed a paper that may have opened a door to an entirely new area of research in computer security.