Paper Info
- Paper Name: Igor: Crash Deduplication Through Root-Cause Clustering
- Conference: CCS ‘21
- Author List: Zhiyuan Jiang, Xiyue Jiang, Ahmad Hazimeh, Chaojing Tang, Chao Zhang, Mathias Payer
- Link to Paper: here
- Food: Tiramisu
Paper Summary
While fuzzing is a valuable tool for finding software crashes, these crashes are often not unique and need to be analyzed in order to find the root causes which actually need to be fixed. Existing approaches to mitigating this problem, such as coverage-based uniqueness or stack hashing, come with their own tradeoffs and can overestimate crashes by orders of magnitude. Igor is a new tool to address this issue, working in two phases to first flip the fuzzing process on its head and minimize coverage in order to trim execution traces as much as possible before deduplication and then use CFG similarity to cluster crashes from there.
Coverage-minimizing fuzzing
The core of Igor’s approach is to attempt to turn all crashes into the shortest possible path to reach that same bug, hopefully removing redundant info or noise from the execution trace. Existing approaches focus on constraining the size of the crashing input itself rather than the execution trace; for instance, AFL-tmin attempts to minimize the crashing input and even when reducing input size by ~85% leads to ~15% of crashing inputs following more CFG edges than before minimization. Clearly input minimization is far from a perfect proxy for trace minimization, and as such Igor’s fitness function favors traces with fewer edges. Their evaluation of this minimization approach found zero false positives (e.g. a supposedly minimized input actually triggering a different bug) in the minimization of 5,535 PoCs.
Clustering
Their approach to clustering relies on CFG similarity, computed using the Weisfeiler-Lehman Subtree Kernel. Unlike graph/subgraph isomorphisms which give binary results on graph similarity, this kernel method outputs a similarity matrix suitable for use in clustering. The silhouette score, a measure of clustering quality, is used as a metric to evaluate the results. Spectral clustering relies on knowing the number of clusters in advance, and attempting to compare the results of various cluster counts by silhouette score may still underestimate the true number of clusters. In this case, manual review of the first-stage clustering may indicate another pass of clustering is in order.
Evaluation
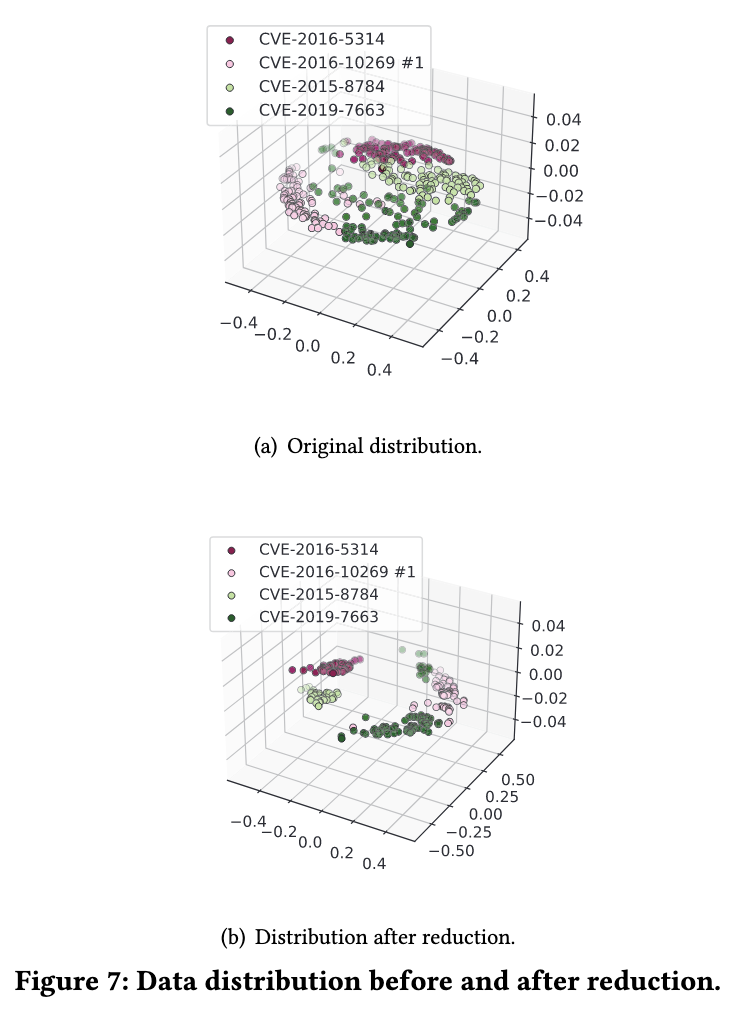
Running IgorFuzz for their recommended default cutoff time of 15 minutes, beyond which they observed diminishing returns, led to a 14.4% improvement in silhouette scores. While not the easiest to interpret, this does represent substantial improvment to crash clustering. Figure 7 from the paper illustrates crash clusters before and after test case reduction using Igor and is far more intuitive than interpreting the data on silhouette scores.
Preliminary Reviews
| RevRec | RevExp | OveMer | RevInt | WriQua | EthCon | |
|---|---|---|---|---|---|---|
| Review #4A | 4/6 | 2/4 | 3/5 | 2/3 | 3/5 | 1 |
| Review #4B | 5/6 | 2/4 | 4/5 | 2/3 | 4/5 | 1 |
| Review #4C | 5/6 | 3/4 | 3/5 | 2/3 | 4/5 | 1 |
Discussion
Summary of Strengths and Weaknesses
Overall, the class found Igor to be a very strong paper, with x2 straight accepts and only x1 minor revision. Common strengths brought up were the novelty of the techniques described, the high impact of its results and the excellent use of tables and graphs in the paper. We see this reflected in how every group ranked this paper in the top 25% of papers or more. Two groups felt it was well-written, while the one that considered it merely adequete in their review largely had some minor changes to formatting to make things easier to follow. We can see this as an endorsement of the paper’s core contributions. Other strengths mentioned were the availability of Igor’s source code and the papers detailed evaluation breakdown of Igor’s results.
Conversely, perhaps due to the strength and focus of the paper, it was difficult for groups to identify major weaknesses, or at least weaknesses they felt strongly about. Much of the discussion was focused on trying to actually find weaknesses in the paper, since its strengths were agreed upon and seem to be topics that had been discussed before (the importance of novelty and the importance of good graphs/writing). Reviewers with a background in machine-learning then brought up how the ML specific techniques used by Igor were crude and sometimes self-contradictory (details to be discussed in the section below), a fact that reviewers unfamiliar with the field could not pick up on. This highlights the importance of having field-related specialists ‘vet’ claims made by a paper when reviewing it.
Resource Usage aka The Worth of a Research Tool
Eventually, the discussion turned to the second major ‘weakness’ of the paper: its implementation efficiency. The authors in the paper made claims that Igors’ computational costs were relatively low and acceptable. Reviewers felt that these claims were questionable given the high resource usage of the equipment used and the actual performance numbers cited (52 cpu-years). Comparisons to other state-of-the-art programs focused on the improvement in bug counts, but glossed over their relative speeds, which as one reviewer put are “lightning fast in comparison [to Igor]”. That said, discussion felt that while the implementation was questionable, the key ideas behind the techniques used are sound, and thus such improvements could be relegated to a ‘future work’ instead and should be weigh too heavily against the paper itself.
This led to a wider discussion on evaluating performance and resource usage in the real world - how time costs and money are related, and how this influences the eventual adoption of a tool - i.e. at what point is a particular research effort ‘worth it’. An important thought experiment brought up was the notion of relative time-costs saved i.e. if a tool saved you 10 minutes on a task everyday, but cost 100k to operate, under what scenario would it be worth adopting? On one hand, such thought experiments are valuable when evaluating and comparing tools from a business perspective. On the other, how relevant is it to discuss the adoptability of a reserach tool designed to push boundaries instead of marketability? Even with the apparent high performance costs, all groups still felt the research was sound. One reviewer pointed out that the authors were not so much deliberately obscuring how much slower Igor is as choosing to focus the paper on more key contributions and limitations - a choice that did pay off, considering the paper was eventually accepted. In the end, while no real conclusion was reached, the discussion did bring up a few important points: 1) that comparisons, when made during evaluation, should be made fairly using the same baselines 2) that considering extremes (as boundaries) can be useful when evaluating and 3) that every paper is series of choices and tradeoffs made by the author on both the research and what to put in the paper itself - and it is important to be cognizant of these choices when writing or reviewing a paper.
ML Techniques
The reviewers liked how the authors added Machine Learning clustering aspect to the paper. Some mentioned that the clustering was weird - not the exact process of clustering but they claim that they cannot use k-means clustering for their data but they picked a clustering method that uses k-means clustering technique as an underlying clustering functionality. Moreover, they mention CPU resource problems but they use scikit-learn which is known to be slow in the machine learning community. It seemed that a machine learning expert would probably be able to process the data using a better pipeline. It is not the pipeline that the reviewers disagreed with, just the tools they have used. They have used tensorflow for the experiments. It is simple to do clustering with scikit-learn by loading the data and instructing it to fit the data. They have also picked the only clustering algorithm that does not require them to specify any initial number of clusters in the beginning. By looking at their code, it seems that they literally just repeatedly tries to fit the data in the loop and then picks the best result out of the range of possible bugs account. Their results were pretty good though. Adopting a better approach may have speed-up their experiments a lot. The idea of using machine learning algorithm as pipeline is novel.
Accessibility note
Figure 2 is a function call graph with very small nodes and edges solely differentiated through the use of red and green. While it was not crucial to following the paper in this case, taking colorblindness (and by proxy, black-and-white print-friendliness) into account when designing graphics is an important effort to make.