Paper Info
- Paper Name: FuzzGen: Automatic Fuzzer Generation
- Conference: USENIX Security ‘20
- Author List: Kyriakos Ispoglou, Daniel Austin, Vishwath Mohan, Mathias Payer
- Link to Paper: here
- Food: Pairs well with peanut butter cookies
Introduction
Fuzzing is a great way to find bugs. Nobody contests this. However, fuzzing libraries is hard because their APIs are generally not designed to be resilient against malformed data at the ABI level - indeed, if you pass an invalid pointer to memcpy, the program will crash in libc, and this is not a bug in libc.
Because of this, the general technique for fuzzing libraries is to write a “harness”, a program which can take an entropy source and transform it into a meaningful series of API calls. Writing these harnesses is a very time-consuming and tedious part of bug-finding, and so this paper aims to automate this process.
FuzzGen, the tool which is the paper’s main contribution, works by analyzing the library and its clients to infer API requirements, and then synthesizes a harness which links against the library and can be hooked up to a fuzzer.
Analysis
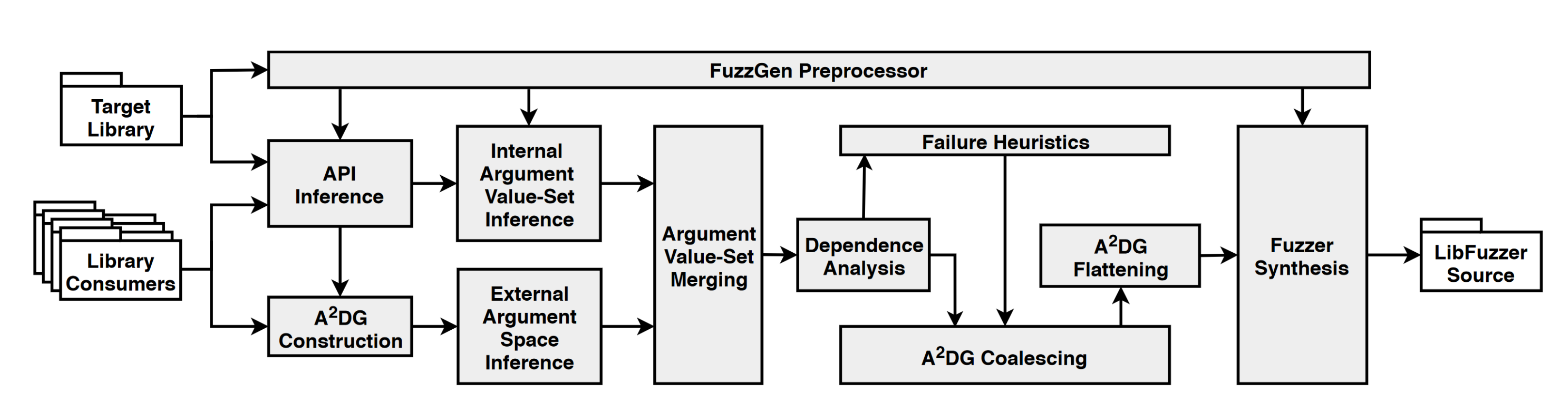
First, FuzzGen identifies the API that will be fuzzed by intersecting the names of the exported functions in the library object with the names of the exported functions in the library’s header files. Then, it scrapes the filesystem for binaries which link against that library and use these APIs. Once it has the client libraries, it can begin its main analysis phase.
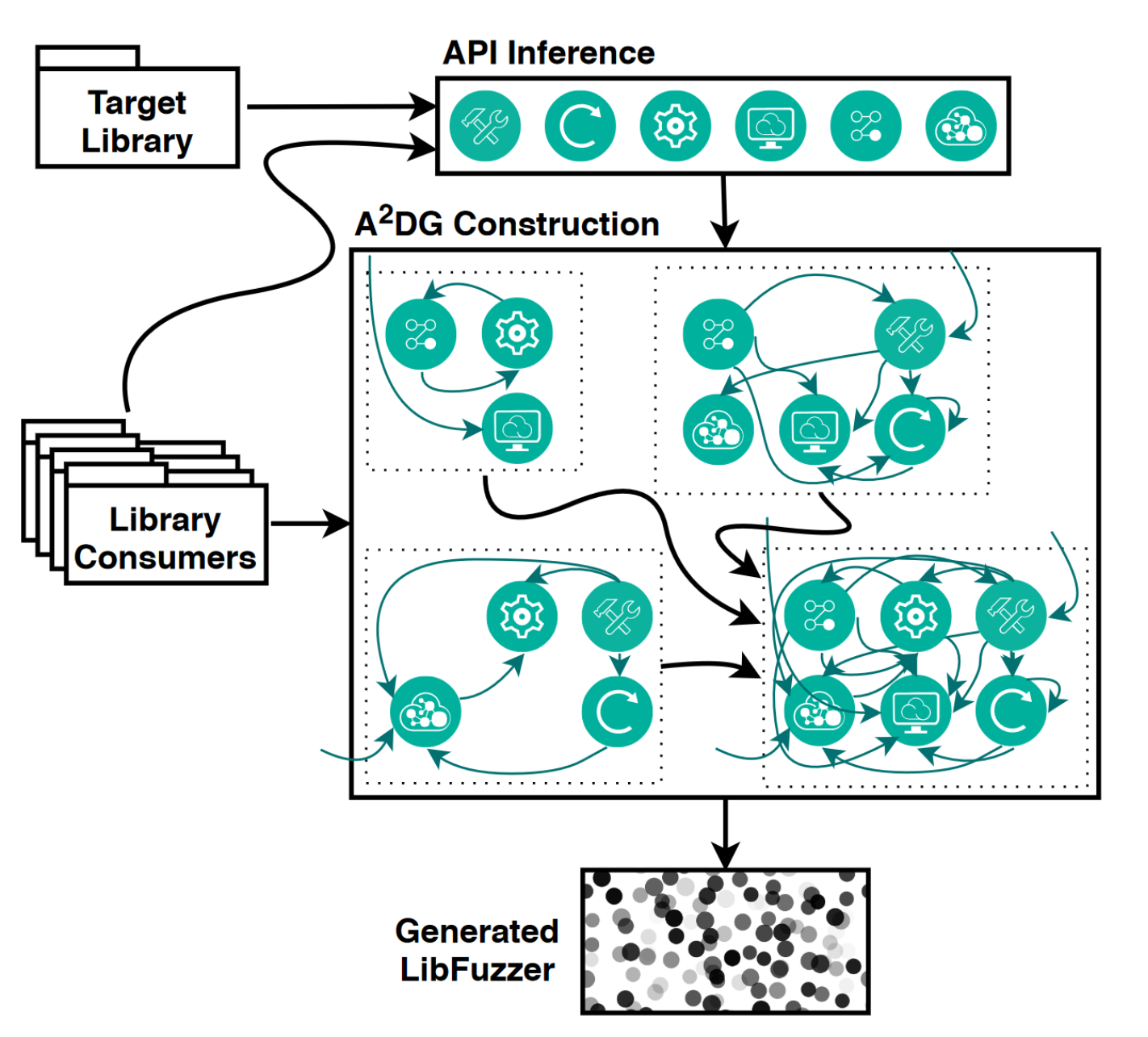
The A2DG
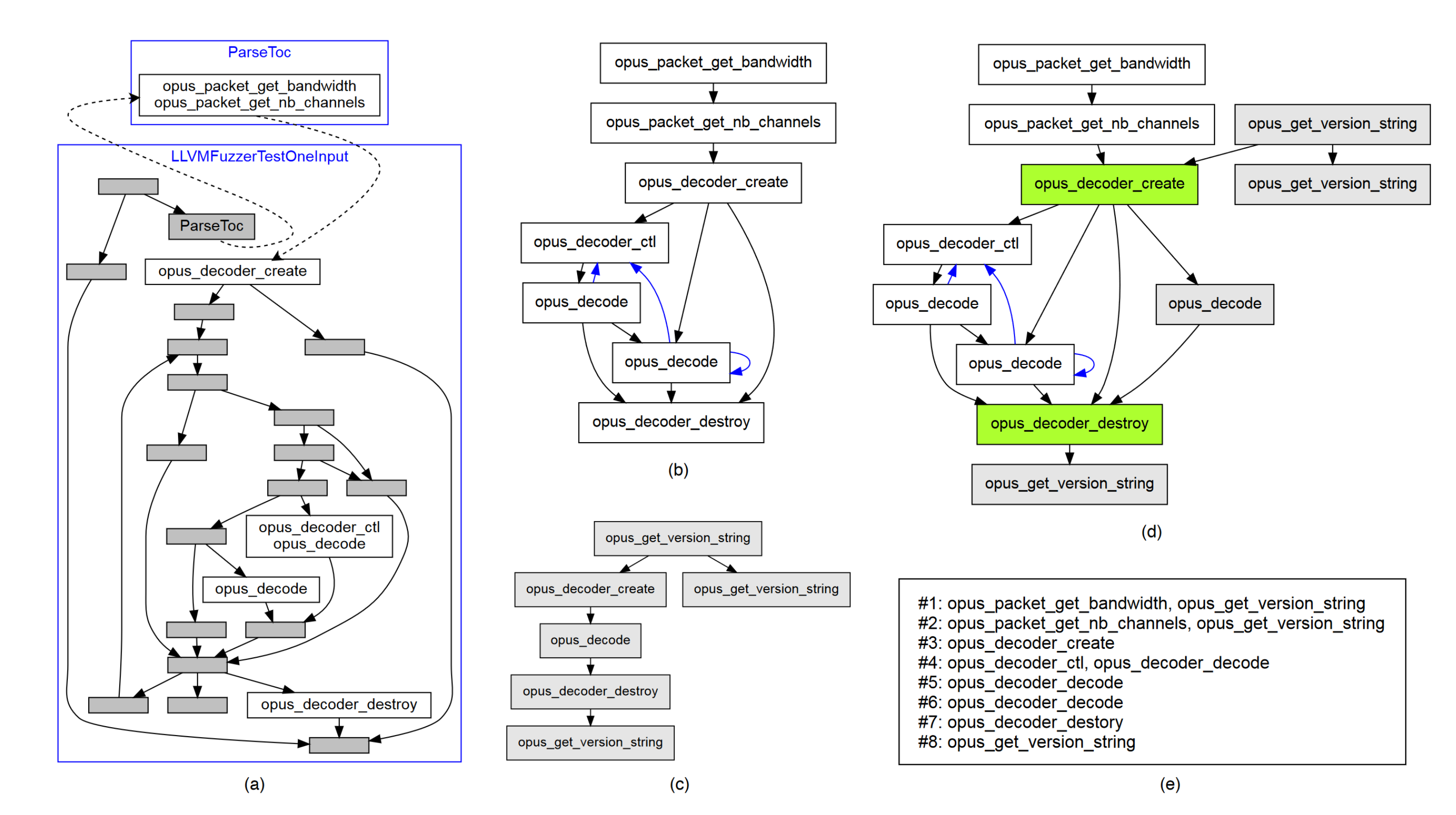
FuzzGen constructs an Abstract API Dependency Graph (A2DG). This graph represents the complicated interactions and dependencies between API calls, allowing the fuzzer to satisfy these dependencies. It exposes which functions are invoked first (initialization), which are invoked last (tear down), and which are dependent on each other. This graph encapsulates both data flow dependencies as well as control flow dependencies.
Argument flow analysis takes place on the A2DG. This is done using heuristics to determine which arguments have to do with the context, such as handles, file descriptors, etc. These should not be fuzzed. The type of each argument is determined. The value bounds for each argument is determined. The dependencies between arguments across functions are determined. These constraints are to be maintained while fuzzing.
Control flows which are identified as error conditions (through heuristics) are discarded. The control flow portion is distilled into only the nodes which are calls to the library.
This graph is then flattened to prevent state explosion during traversal. This is done by removing back edges and preforming a relaxed topological sort. All of the A2DGs of the multiple considered consumers are merged together.
Fuzzing
The fuzzer stub is synthesized from the prior analysis. This fuzzer stub attempts to balance both depth and breadth of program explorations. This stub uses an entropy source (the fuzzer), and transforms that randomness into a set of API calls.
Evaluation
Evaluation needs to have a sufficient number of test runs, a sufficient time period, and standardized common seeds. To this end, targets were fuzzed 5 times for 24 hours. The targets against which it evaluated was 7 widely used audio/video codecs, which have a large attack surface. The fuzzer stub produced by FuzzGen was compared against a manually created fuzzer stub produced by the paper’s authors. The consumers to analyze were chosen by picking the ones with the highest density of API calls. Clang’s Sanitizer Coverage mechanism was used to determine the code coverage.
Discussion
We had several concerns regarding the evaluation methodology.
First, we question the comparison between manually written fuzzer stubs versus automated fuzzer stubs. The fact that the stubs written by the authors were outperformed by the automated fuzzers may suggest that the manual fuzzers were underperforming. We are interestested in further understanding what about the automation was actually better than the manual harnesses in the cases that did outperform the manual fuzzer. In general, we would expect that this process makes automatically fuzzing libraries possible, but that humans would still outperform this process. However, it is possible that this analysis process is better able to reasonable about potentially complex library interactions at a massive scale compared to humans.
We are also curious about the library selection process. This evaluation only targets codec libraries. These libraries, despite being different, nevertheless all operated on only a small handful of codecs, which may look very similar from the perspective of fuzzing. We would have liked to see a more diverse set of libraries.
More than anything, though, we would have liked to see a large scale analysis of FuzzGen. An analysis across hundreds, maybe even thousands, of libraries would be useful to better understand how this technique works at scale. After all, it seems that the primary selling point of this paper is the ability to do library harnessing at scale. Such an evaluation could demonstrate that this technique is able to produce harnesses at scale which are able to produce coverage improvements beyond or quicker than what is capable by a program being fuzzed which uses that library.