Paper Info
- Paper Name: FREEDOM: Engineering a State-of-the-Art DOM Fuzzer
- Conference: CCS ‘20
- Author List: Wen Xu, Soyeon Park, Taesoo Kim
- Link to Paper: here
- Food: Cookies
Problem
Web browsers have lots of high-severity bugs. The DOM (Document Object Model) engine, responsible for displaying interactive HTML documents, has extraordinary complexity, and is one of the largest bug sources in a web browser.
Smart fuzzing is the dominant approach for finding bugs within DOM engines, but are lacking for multiple reasons:
- Static context-free grammars
HTML documents have rich semantics reflected by data dependencies within the document. Existing DOM fuzzers fail to manage these dependencies, and as a result, suffer from semantic errors in their output documents. This naturally results in a worse exploration of the state space.
- Lacking intermediate representation
Existing DOM fuzzers output textual documents without preserving intermediate information. As a result, the generated documents can only be mutated by appending new data rather than by many other operations such as data flipping and splicing.
- Poor handling of program termination
Launched browser instances never automatically terminate unless a crash occurs. It is difficult to know exactly when the input document is completed processed because of dynamic rendering tasks that may occur anytime. As a result, existing DOM fuzzers set a timeout of 5-10 seconds. This results in a severely low throughput. Less throughput means less state exploration.

Solution
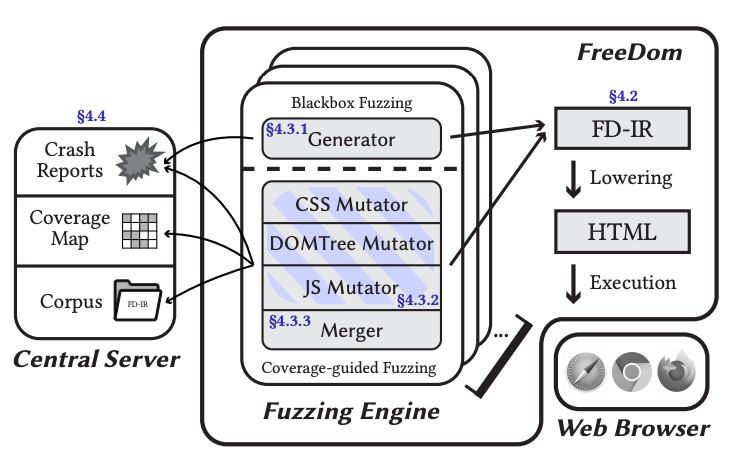
To resolve Problem 1 and 2, this paper presents FD-IR, an intermediate language(IR) that captures the semantic and context information of valid HTML documents. In FreeDom, the fuzzer describes HTML documents in FD-IR and then lower the IR into valid HTML documents. These HTML documents will be fed into browsers for testing purpose.
FD-IR captures global context and local context separately to properly handle context information like class names. Besides, it uses a general purpose Value object to represent different components in an HTML document, such as: elements in the DOM Tree, CSS rules etc. To extend the capability of FD-IR, one only needs to provide the implementation details of a new Value object.
In short, the design of FD-IR provides the ability to generate stateful, context-aware and extensible description of HTML documents.
To resolve Problem 3, the authors patch the target browsers to make them dynamically kills themselves when the loading process of an input document is mostly completed. This technique brings significant execution speed boost and results in very few missed crashes.
FreeDom can generate valid FD-IRs and lower them into valid HTML files. Since FreeDom internally handles testcases in FD-IR, it is also able to mutate the FD-IR based on the syntax and semantic information embeded in the IR. For example, it is able to mutate a Value object in a FD-IR representation to create another valid HTML document for single document mutation. Similarly, it is able to merge two different FD-IR representations together for creating a new input.
Discussion
The discussion section of the paper highlights some of the limitations of FD-IR. Notably that they can’t yet parse existing HTML documents into their immediate representation, and they don’t try to address each browser’s slight differences from eachother. However, they state that browser differences can be handled by selectively toggling DOM features depending on the target browser. The authors also discuss how FD-IR could be generalized to target other tree-like formats such as PDFs and other hierarchical filesystems.
Another discussion topic is the potential of coverage-driven DOM fuzzing by discussing areas of future work for this area. The author’s highlight a number of methods to improve:
Corpus-based fuzzing: Currently FD-IR (as mentioned earlier) doesn’t support parsing existing HTML documents, however, once they can leverage existing test suites to start from, FreeDom will likely have much better performance.
Better seed scheduling: Currently FreeDom mutates test cases based on which ones are the most recently generated, however, there are lots of testcase scheduling algorithms that outperform this that could be implemented.
Non-compliant document fuzzing: One of the other large areas of potential growth is the handling of documents that don’t strictly adhere to the DOM standard. All mainstream browsers currently will attempt to load a non-standard document as well as possible by performing actions such as autocompleting unclosed HTML tags and many other methods. FD-IR currently isn’t able to handle these types of documents due to strict adherance to the DOM standard. However, this support would increase FreeDom’s performance.
Ultimately, this paper utilizes a known concept of using an intermediary representation to fuzz and applies it to DOM fuzzing. While this paper does have some significance due to the theoretical generalization of their solution, their explanation of how the solution actually worked felt lacking due to just how abstract it was.