Paper Info
- Paper Name: Datalog Disassembly
- Conference: USENIX Security ‘20
- Author List: Antonio Flores-Montoya and Eric Schulte, GrammaTech Inc.
- Link to Paper: here
- Team: Team Stapler
- Food: Pairs well with cookies
Datalog Disassembly
Abstract
Disassembly is fundamental to binary analysis and rewriting. We present a novel disassembly technique that takes a stripped binary and produces reassembleable assembly code. The resulting assembly code has accurate symbolic information, providing cross-references for analysis and to enable adjustment of code and data pointers to accommodate rewriting. Our technique features multiple static analyses and heuristics in a combined Datalog implementation. We argue that Datalog’s inference process is particularly well suited for disassembly and the required analyses. Our implementation and experiments support this claim. We have implemented our approach into an open-source tool called Ddisasm. In extensive experiments in which we rewrite thousands of x64 binaries we find Ddisasm is both faster and more accurate than the current state-of-the-art binary reassembling tool, Ramblr.
The Problem
Reverse engineering x86/x64 binaries is a non-trivial activity. This has historically prevented the unauthorized creation or modification of derivative works, but there are cases when the modification of compiled code is a good thing, and sometimes the only option available to solve certain problems. Let’s say a security flaw is discovered, and the authors no longer support or no longer have the original source code. The only options are either to patch the binary, or ignore the security flaw or replace the program, options that often are extremely costly. Many times security patches are time critical. There are times when there is a benefit to modifying malware, and many similar cases when obtaining the source code might be feasible but difficult.
Binary Rewriting Challenges 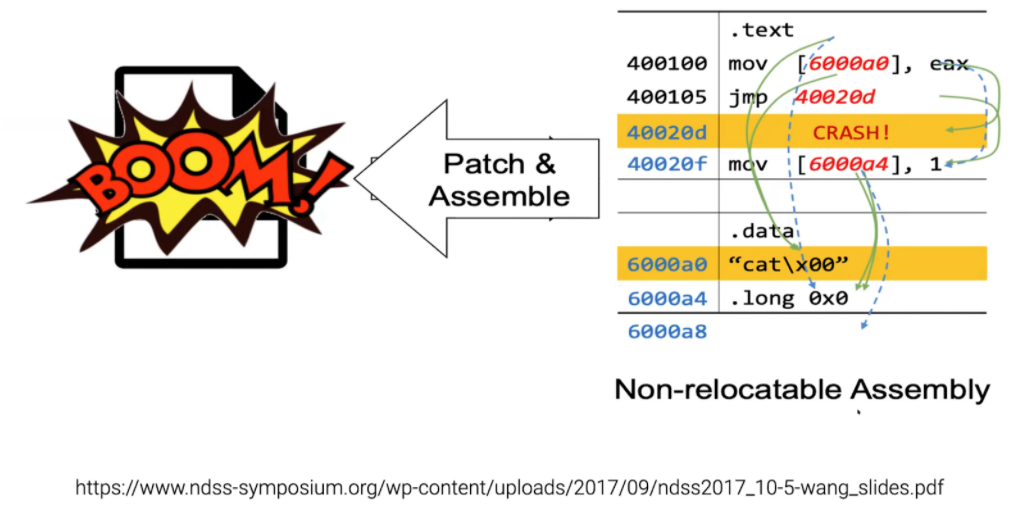
Many characteristics of the compilation process make reverse engineering difficult. The data/instruction boundary is unclear. Determining this boundary is a major challenge addressed by datalog. Within the data itself, it is not clear if values are literals or references. During execution, these determinations can be made by the instruction being executed, but static analysis cannot determine this as easily.
Referential integrity is another major issue. Changing the length of a program invalidates large numbers of hardcoded jump addresses that were substituted at compile time. How do you identify all of the pointers as pointers, so they can be shifted in value, while not modifying any literal values? 
Even RIP-relative addressing, often considered to be “indirect addressing” will be damaged if additional instructions are inserted between the jump call and the function it is calling. In this example, an additional nop instruction will lengthen the code longer than the hardcoded 15-bytes used by the jump call when jumping to the “call func2” (RIP-relative addressing is immune from code insertions outside of this window)
Disassemblers
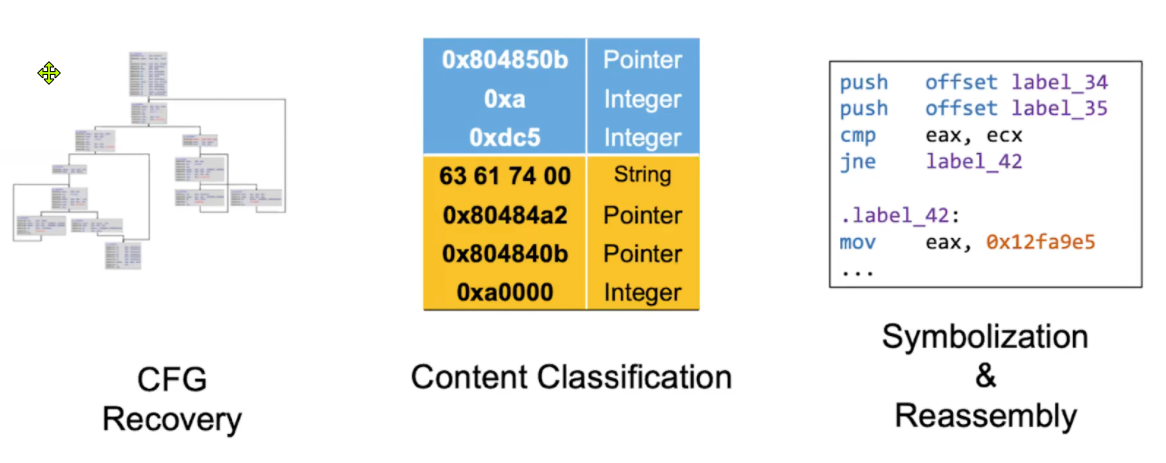
To tackle all of these problems, disassemblers generally will perform the following functions
CFG Recovery: Rebuilding the control flow graph from the binary code
Content Classification: Identifying data types. Which variables are pointers and which variables are values. Two of the most common problems when disassembling occur during the step. False positives occur when variables are mistaken for pointers and are modified incorrectly in response to program changes. False negatives occur when pointers are mistaken for values and are not modified.
Symbolization and Reassembly: Rebuilding usable code by rebuilding the relationships between sections of code, translating offsets into labels that can be used instead of hardcoded numerical values.
All hardcoded values must be symbolized, including numerical values and RIP-relative jumps. . This is done by building a constraint solving problem. Each of these rules must be maintained to ensure the integrity of the disassembled code. For example if a new instruction is added that has a size of ‘E,’ it is necessary to determine which jumps must be increased by size(E), and traverse down to other rules that may be affected by this change recursively until all necessary changes are found. 
The general process that Rambler & Ddisasm follow is to first create a series of rules that describe how this section of code works, add something comparable to a new rule, and then verify all constraints, all of the pre-existing rules & ensure that they remain true. If the new rule causes a logic contradiction, the new rule is rejected.
Motivation
The state of the art disassembler solution Ramblr uses static program analysis along with heuristics to rebuild the underlying program. Datalog does not introduce anything to the disassembler process that provides any additional power or capability that doesn’t exist in previous solutions. What it does provide is a faster decompilation process and a more accurate assembly code representation than the current state-of-the-art. Ddisasm takes the binary and produces an intermediate representation called GTIRB that can be directly printed to assembly code and directly assembled. Datalog itself can be thought of as a JSON database, and you insert facts into this database generated by parsing through the code using Python.
Overview
Terminology
Datalog is a declarative language that can be used to express dataflow analyses very concisely Instruction boundary identification (IBI) amounts to deciding, for each address x in an executable section, whether x represents the beginning of an instruction or not. Symbolization amounts to deciding for each number that appears inside an instruction operand or data section whether it corresponds to a literal or to a symbolic expression and what kind of symbolic expression it is.
High Level Design
The high level approach for each of these decisions is the same. A variety of static analyses are performed that gather evidence for possible interpretations. Then, Datalog rules assign weights to the evidence and aggregate the results for each interpretation. Finally, a decision is taken according to the aggregate weight of each possible interpretation. Our implementation infers instruction boundaries first (described in Sec. 4). Then it performs several static analyses to support the symbolization procedure: the computation of def-use chains, a novel register value analysis, and a data access pattern analysis described in Sec. 5.1, 5.2, and 5.3 respectively. Finally, it combines the results of the static analyses with other heuristics to inform symbolization.
Eval Overview
We compare the precision of the disassemblers by making semantics preserving modifications to the assembly code—we “stretch” the program’s code address space by adding NOPs at regular intervals—reassembling the modified assembly code, and then running the test suites distributed with the binaries to check that they retain functionality
We evaluate the symbolization step by comparing the results of the disassembler to the ground truth extracted from binaries generated with all relocation information. Finally, we compare the disassemblers in terms of the time taken by the disassembly process.
Datalog Overview
Representing binaries in Datalog
Logic programming takes a set of facts and a set of rules and generates new predicates from them by repeatedly applying inference rules to the facts. For disassembly, information about the binary are facts and disassembly procedure(with additional auxiliary analysis) constitute the rules.
Domains defined for representing binaries:
- S: set of strings.
- Z64: Set of 64 bit numbers.
- A: set of addresses; subset of Z64.
- R: register names; subset of S.
- O: operand identifiers; also subset of Z64
Predicates use for representing facts:
- I for instructions: address(A), size(Z64), prefix(S), opcode(S), op1: O, op2: O, op3: O, op4: O
- invalid: address(A). Used if no valid disassembly is possible.
- op_regdirect: op(O), register(R) for registers operands.
- op_immediate: op(O), immediate(Z64) for immediate operands.
- op_indirect: op(O), reg1(R), reg2(R), reg3(R), mult(Z64), disp(Z64), size(Z64). For access of the form reg1:[reg2 + reg3 * mult + disp] (eg: ds:[rsi + rcx * 4 + 2]).
Initial set of facts
- All possible instructions by disassembling starting at every byte. Success => I, failure => invalid. Operand IDs stored in I; operands stored separately and can be found using the ID.
- data_byte(A, Val): the byte at address A. Stored for both data and executable section.
- address_in_data(A, Addr): A is one of the 8 bytes referenced by Addr. Done for both data and executable section.
- More facts from section, relocation and symbol tables as well as entry point of executable.
- For libraries, all exported functions are entry points.
Fallthrough
An instruction “falls through” when the control flow reaches the address immediately adjacent to it (i.e., the start of the instruction plus the instruction’s size). An instruction must fallthrough when the instruction’s execution always reaches the adjacent instruction. For example, a mov instruction will always reach the adjacent instruction. An instruction may fallthrough when the instruction’s execution will sometimes reach the adjacent instruction. For example, the instructions invoked by a call instruction may never issue a return.
1
2
3
4
5
6
7
8
9
10
11
12
13
may_fallthrough(From,To):−
instruction(From,Size,_,OpCode,_,_,_,_),
To=From+Size,
!return_operation(OpCode),
!unconditional_jump_operation(OpCode),
!halt_operation(OpCode). (Rule 1)
must_fallthrough(From,To):−
may_fallthrough(From,To),
instruction(From,_,_,OpCode,_,_,_,_),
!call_operation(OpCode),
!interrupt_operation(OpCode),
!jump_operation(OpCode),
!instruction_has_loop_prefix(From). (Rule 2)
Using Rule 1, an instruction may fallthrough when it is not an unconditional jump, not a return, and not halt.
Using Rule 2, an instruction must fallthrough when it may fallthrough and it is not a call, is not an interrupt, is not a jump, and is not a loop.
Instruction Boundary identification
Step 1: Backward Traversal
The backward traversal simply expands the amount of invalid predicates through the implication that any instruction unconditionally leading to an invalid instruction must itself be invalid.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
invalid(From):−
(must_fallthrough(From,To) ;
direct_jump(From,To) ;
direct_call(From,To) ;
pc_relative_jump(From,To) ;
pc_relative_call(From,To)),
(invalid(To) ;
!instruction(To,_,_,_,_,_,_,_)). (Rule 3)
possible_effective_address(A):−
instruction(A,_,_,_,_,_,_,_), !invalid(A). (Rule 4)
code_in_block_candidate(A,A):−
possible_target(A),
possible_effective_address(A). (Rule 5)
code_in_block_candidate(A,Block):−
code_in_block_candidate(Aprev,Block),
must_fallthrough(Aprev,A),
!block_limit(A). (Rule 6)
code_in_block_candidate(A,A):−
code_in_block_candidate(Aprev,Block),
may_fallthrough(Aprev,A),
(!must_fallthrough(Aprev,A) ;
block_limit(A)),
possible_effective_address(A). (Rule 7)
possible_target(A):−
initial_target(A). (8)
possible_target(Dest):−
code_in_block_candidate(Src,_),
(may_have_symbolic_immediate(Src,Dest) ;
pc_relative_jump(Src,Dest) ;
pc_relative_call(Src,Dest)). (Rule 9)
Step 2: Forward Traversal
It traverses the code recursively but is much more aggressive than typical traversals in terms of the targets that it considers.
What are 2 mutually recursive predicates?
Rules 5 - 10
A possible target, marks the beginning of a new basic block candidate (Rule 5). The candidate block is then extended as long as the instructions are guaranteed to fall through and we do not reach a block_limit (Rule 6). Rule 7 starts a new block if the instruction is not guaranteed to fall through or if there is a block limit. Any addresses or jump/call targets that appear in a block candidate are considered new possible targets (Rule 9). (More aggressive than typical analysis that only considers targets of jumps or calls). Rule 10 adds a linear-sweep component to the traversal.
At the completion of the forward traversal, an over-approximated list of basic blocks exists (where some of the BB’s are invalid).
Step 3: Solving Block Conflicts
The next step is to decide which candidate blocks are real. If two blocks overlap, then it is assumed one of them is invalid. Block conflicts are solved using a set of heuristics that are mainly based on how blocks are interconnected, how they fit together spatially, and whether they are referenced by potential pointers or overlap with jump tables. Some of the heuristics used are described below (+ for positive points and − for negative points):
- The block is called, jumped to, or there is a fallthrough from a non-overlapping block.
- The block’s initial address appears somewhere in the code or data sections. If the appearance is at an aligned address, it receives more points.
- The block calls/jumps other non-overlapping blocks. − A potential jump table overlaps with the block. All memory not covered by a block is considered data.
Auxiliary Analysis
Register Definition-Uses Analysis
1
2
3
4
5
6
7
8
416C35: mov RBX, -624
416C3C: nop
416C40: mov RDI, QWORD PTR [RIP+0 x25D239]
416C47: mov RSI, QWORD PTR [RBX+0 x45D328]
416C4E: mov EDX, OFFSET 0x45CB23
416C53: call 0x413050
416C58: add RBX, 24
416C5C: jne 0x416C40
A static analysis that infers definitions and uses in the code. A definition occurs when a register a register value is set at an address. For example, consider the following line from the assembly above: 416C35: mov RBX, -624 This code results in the predicate def(416C35, RBX).
Next, the use occurs at instruction 416C47: mov RSI, QWORD PTR [RBX+0x45D328] when RBX is used as the base pointer and resulting in the predicate use(416C7, RBX).
Putting these together results in a def_used(Def Address, Register, Use Address, Use Index) predicate and putting together the definition and use above results in def_used(416C35,’RBX’,416C47,1).
Note, the Index is 1 in this case because it is the first use of the register. A subsequent use of RBX at 416C58 will result in def_used(416C35,’RBX’,416C58,2).
Next, the tool determines which def_used predicates are used to compute addresses that access memory and denotes them with def_used_for_address(Adef:A,Reg:R)
Register Value Analysis
A relatively simple analysis that captures the kind of register values that are typically used for accessing memory. The first phase produces predicates for each instruction and def-use predicate. Then it chains together the predicates with the instructions.
Detecting Simple Loops
The tool detects when a register is initialized to a constant and then incremented/decremented in a loop by a constant.
Multiple Register Operations
The base predicate reg_val does not support the use of multiple registers; however, an additional analysis step attempts to resolve the registers into a single register.
Data Access Pattern Analysis
Combines the results of the register value analysis and def-use analysis to infer the register values at each of the data accesses to compute the accessed addresses.
Symbolization
False positives occur when the tool identifies an address as a pointer, but it is actually a value. False negatives occur when the tool identifies an address as a value, but it is actually a pointer.
False Positive: Value Collisions
False positives are due to value collisions, literals that happen to coincide with range of possible addresses. In order to reduce the false positive rate, we require additional evidence in order to classify a number as a symbol.
False Negatives: Symbol+Constant
False negatives can occur in situations where the original code contains an expression of the form symbol+constant. In such cases, the binary under analysis contains the result of computing that expression
Evaluation
The authors compare their tool, Ddisasm, with the most recent state-of-the-art tool Ramblr.
Benchmarks
106 binaries from Coreutils 8.25 69 binaries from the Cyber Grand Challenge set compiled into x64 25 binaries from real world open source applications (sizes ranging from 28k to 2.5mb) 200 Total binaries compiled using 7 compilers (GCC 5.50, GCC 7.10, GCC 9.2.1, Clang 3.8.0, Clang 6.0, Clang 9.0.1, and ICC 19.0.5) and 6 different optimization flags (-O0 through -O3, -Os, and -Ofast) for a total of 7658 binaries (coreutils binaries compiled with -Ofast were excluded b/c they failed the baseline tests).
Symbolization Experiments
The authors disassembled each binary using both tools and found the symbolization false positives and false negatives. They obtained the ground truth for comparison using the relocation information generated by the the -emit-relocs ld linker option.
Functionality Experiments
Using the same benchmarks the authors checked how many of the disassembled binaries can be reassembled and how many of those pass their original test suites without errors. The experiment added NOPs to the code and added 64 zero bytes to the beginning of each data section. After reassembling, they checked the resulting binary using its test suite.
Ddisasm works on stripped binaries but Ramblr does not.
Performance Evaluation
On average, Ddisasm was 4.9 times faster than Ramblr. Only in 294 of 7658 cases was Ramblr faster than Ddisasm.
The x and y axis denote the time it took for Ramblr and Ddisasm to disassemble and reassemble the binaries. The difference between the two graphs is only the increase in time allotted.
Summary of Classroom Discussion
Is binary rewriting a solution in search of a problem? Maybe, but some potential uses other than fuzzing that haven’t been exploited include altering optimizations, static instrumentation, generic hardening, etc.. Possibly too much emphasis in research is spent on “how to apply the patch” compared to “which patch to apply.” Many solutions exist now that solve the disassembly process, but not enough research is spent in effectively or automatically creating patches and situating them in the binary.
To what extent should an evaluation work towards determining why a competitor (Ramblr) in this case isn’t working and make the appropriate alterations? This is an interesting question indeed because a to-be published paper(https://oaklandsok.github.io/papers/pang2021.pdf) said that there is some issue with an angr’s disassembly but it turned out to be a bug introduced due to some recent change in angr. Similarly, many of the papers that evaluated against klee were found to be using klee in some configuration that performed relatively worse and if used differently, the results of those papers could actually be much less significant improvements over klee(https://ieeexplore.ieee.org/document/7886898). Perhaps the author should investigate the actual reason for the issue(specially in case of angr, they could have asked the developers or analysed the code) to determine if it’s a fundamental problem of the technique or some implementation flaw?
Could the technique, using datalog, be extended to other areas of binary analysis? The paper performed rewriting of position-dependent code which makes it pretty significant in what it’s achieved: rewriting position independent code is probably not as challenging since everything is mostly PC relative addressing in position independent code.
