Paper Info
- Paper Name: How Machine Learning Is Solving the Binary Function Similarity Problem
- Conference: USENIX ‘22
Author List: Andrea Marcelli, Mariano Graziano, Xabier Ugarte-Pedrero, and Yanick Fratantonio
- Link to Paper: here
- Food: Pizza and Bagels
Paper Recap
As the presence and influence of AI and machine learning in cybersecurity continues to expand, many research areas are obvserving notable improvements from the new techniques. One such area is binary function similarity, which is the problem of taking the binary representation of two functions and producing a number that denotes how “similar” the two functions are. Because we live in a world of varying development environments, traditional numerical comparison methods fail, and more complex methods must be used. This problem is important specifically because the ability to measure similarity between functions is very valuable in reverse engineering, malware analysis, and vulnerability identification. With the amount of existing research in this area, a reader might think that a broad understanding of the field has been reached, however, the authors of the paper in question believe that no current body of published research can arrive at these broad truths. This is because the authors state that all previous work suffers from either an inability to reproduce/replicate previous results or the evaluation results being too opaque. These two problems lead to there being no clear reseasrch direction for binary function similarity, which this paper sets out to solve.
In the paper, the authors perform a measurement study on binary function similarity, and explore existing research with a focus on recent machine learning powered approaches. They also implement a common measurement platform that includes a test suite and a number of existing techniques extended to all of the architectures present in the test suite. They did this by reimplementing existing methodology to create “primitives” of various solutions to compare against, rather than trying to reproduce the results of over a hundred individual solutions. Specifically, they picked 10 approaches and extended or rewrote them to include in their benchmark. A brief summary of the 10 approaches is provided below (taken from Team Not Yan’s presentation).
- Catalog1: IDA plug-in: fuzzy hash, must be same architecture, examines a fixed length byte signature
- FunctionSimSearch: fuzzy hash developed in industry, partial CFG, architectural independent
- Gemini: efficient graph neural network structure utilizing an ACFG with basic block attributes, manually engineered features
- ICML19: graph matching model from Google/deep mind
- Zeek: abstracts to IR, does dataflow analysis, cross-architecture similarity
- ASM2VEC: uses NLP and OOV workaround, unsupervised learning, must be same architecture
- SAFE: sentence encoder built on ASM2VEC to achieve architectural independence
- Assembly code embedding: Gemini enhancement, unsupervised block level features
- CodeCMR/BinaryAI: function level, IR, uses NLP, GNN and basic blocking embedding
- Trex: recent work - extracts functional traces dynamic execution to learn semantics (also utilizes deep learning and NLP)
Then, two datasets were created: Dataset-1 and Dataset-2. Dataset-1 is 7 popular open-source projects including: ClamAV, Curl, Nmap, OpenSSL, Unrar, Z3,and Zlib. Dataset-2 is built ontop of the evaluation set of Trex, and includes 10 libraries built into already compiled binaries for various architectures/optimization levels: Binutils, Coreutils, Diffutils, Findutils, GMP, ImageMagick, Libmicrohttpd, LibTomCrypt, PuTTy, and SQLite. These two datasets were used to evaluate six different tasks (descriptions taken from paper) across optimization levels (O), compilers/compiler versions (C), bitness (32/64) (B), and architecture (A):
- XO: different optimizations, but the same compiler, compiler version, and architecture.
- XC: different compiler, compiler versions, and optimizations,but same architecture and bitness.
- XC+XB: different compiler, compiler versions, optimizations, and bitness, but same architecture.
- XA: different architectures and bitness but the same compiler, compiler version, and optimizations.
- XA+XO: different architectures, bitness, and optimizations, but the same compiler and compiler version.
- XM: different architectures, bitness, compiler, compiler versions, and optimization.
Finally, there were three sub-datasets used for the last one, XM:
- XM-S: XM for small sized functions (<20 basic blocks)
- XM-M: XM for medium sized functions (>=20 and <=100 basic blocks)
- XM-L: XM for large sized functions (>100 basic blocks
To evaluate this, the area under curve (AUC) of the receiver operating characteristics (ROC) was calculated, along with two commonly used ranking metrics, mean reciprocal rank (MRR) and recall (Recall@K) at different K thresholds. They also evaluated on a vulnerability discovery task, which covered 8 OpenSSL CVEs and selected two router firmwares, compiling 10 vulnerable functions for four architectures (x86, x64, and the two router firmwares, ARM and MIPS 32 bit). Further results and figures are located in the paper and can be referenced if desired. The provided graphs below are for Dataset-1.
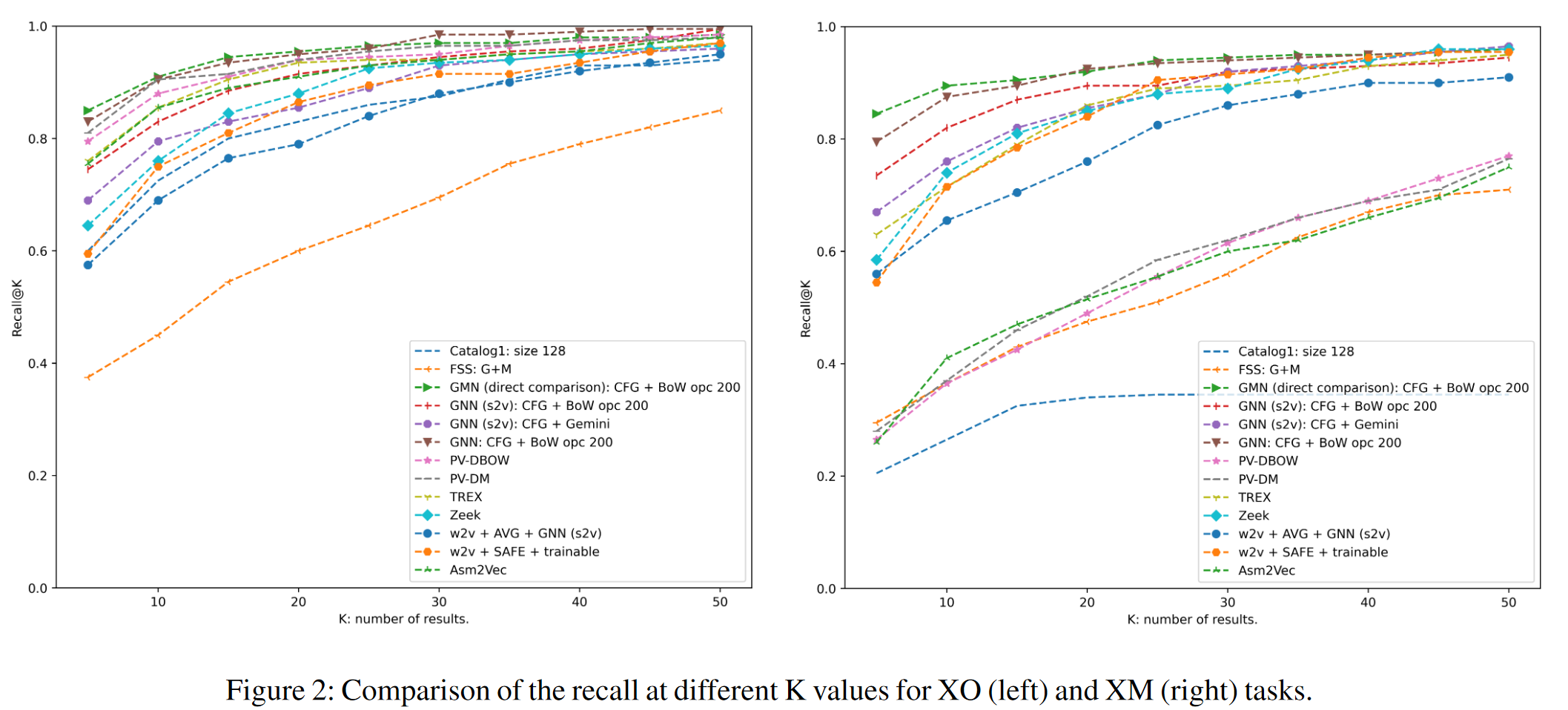
Out of the 10 solutions provided, the ICML19 model outperformed all of the other variants on the six evaluated tasks. Some of the other takeaways include that the fuzzy hasing approaches suffer significantly when multiple compilation variables change at the same time, and that the machine learning models broadly outperform the other methods. With this inform ation, the authors answer a number of broad questions about binary function similarity as a research area, especially with regards to machine learning. Specifically, the authors point out that machine learning models achieve high accuracy even when multiple compilation variables change, and benefit from being trained on ground truth examples based on compilation options. In addition,the choice of the type of model and loss function used are as import as properly selecting input features. Models that use basic block features tend to perform better, but more complex input features tend to not outperform simple ones. It’s also not necessary to train these models for a specific task, since generic task data from XM achieves results close to tailored training for each task. Future research towards the machine learning side is warranted, with the authors noting there are many models that remained untested, although currently GNN models provide the best results.
Discussion
First, it is necessary to note that most people in the discussion were highly appreciative of the leg work this paper did in both:
- Categorizing prior work in the field of AI binary similarity
- Open-sourcing the testing data they used to categorize and evaluate prior work
We thought this paper was well written and gave some valuable overview of the use of AI in the binary similarity problem – even to those less versed with AI. As proof, all four of our reviewing teams Strongly Accepted the paper in their reviews. During the reviewing process and the discussion to follow those reviews (the meta-review), we indulged in a few different questions that analyzed components of the paper, as listed below.
Do we hold authors accountable for summarizing finds?
Throughout the paper’s evaluation, the authors showed a series of metrics that produced numbers to demonstrate the effectiveness of each AI approach to binary similarity; however, these numbers were never summarized or expanded on. Many of our reviewers mentioned that they felt there was no summarization of finds at the end of this paper. We felt the authors lost an opportunity to tell the reader which AI approach they felt was the most effective for solving the problem since it was unclear by the end of the paper. In addition, we felt the authors could’ve explained some underlying concepts in AI that may have made one approach better than the others. We felt the paper was lacking in explaining why these AI concepts worked in the first place, though we do recognize the need to omit details on AI in a security conference.
This paper’s title is “How Machine Learning Is Solving the Binary Function Similarity Problem,” but by the end of the paper, we felt it was unclear how well AI was solving the problem. We felt it hard to understand if modern approaches in AI were strongly beating traditional approaches in this field. This paper could’ve made a deeper impact by explaining if AI is now becoming the superior approach in this field.
How can you apply this evaluation to non-AI approaches?
In connection to understanding the evaluation, we felt the authors could’ve expanded on the applicability of this evaluation to non-AI techniques in the field since both approaches are mostly concerned with the accuracy of their identification of the same function. As described in the paper recap, this paper uses classic AI metrics such as recall to evaluate how well an AI approach identifies the correct function among a series of functions. Though metrics like recall are a solid approach to evaluating AI, it lacks the power to tell the reader who is winning: AI approaches or classic techniques.
Since both traditional and AI approaches care about the same result, we felt this paper was lacking in its evaluation metrics of previous works. We felt there existed a metric that could compare both approaches to each other. As an example, just how much better is Trex than the classic BinDiff? Questions like these are paramount to helping the general scientific community understand the effectiveness of various approaches in a field.
How much is too little data?
On a continued note of the evaluation, we had trouble understanding if the amount of data and the variance in it was enough to warrant a sound and non-biased evaluation of AI approaches. Dataset-1 and Dataset-2 contained a series of binaries from various projects, which we felt was good. Dataset-2 already has a background in the field as it was used in previous works’ evaluation of effectiveness; however, Dataset-1 stumped us on why it had been chosen. The authors did not expand on why those had been chosen. As an alternative, we felt that choosing the top n binaries from apt might have been a better approach as it would’ve eased the question of whether the binaries chosen were too similar to each other.
With any AI paper, we feel the author has a strong duty to prove to the reader that the data is non-biasedly selected for evaluation. As an example, if the author chooses a series of binaries that were HTTP server implementations, the question would arise if the AI approaches were just good at doing binary similarity in binaries that implement HTTP servers. We also wonder if choosing this many binaries would’ve flown for a paper that evaluates a new Binary Similarity approach that does not use AI.
Conclusion
In conclusion, we felt this paper had some solid contributions to the field of Binary Similarity by expanding and categorizing AI approaches. Although we thought the paper had more to explain, such as what strategies are doing better and why we believe this paper pushed the field forward (in the right direction). We look forward to future works from the author.