Paper Info
- Paper Name: Agamotto: Accelerating Kernel Driver Fuzzing withLightweight Virtual Machine Checkpoints
- Conference: USENIX Security ‘20
- Author List: Dokyung Song, Felicitas Hetzelt, Jonghwan Kim, Brent Byunghoon Kang, Jean-Pierre Seifert, Michael Franz
- Link to Paper: here
Abstract
Kernel-mode drivers are challenging to analyze for vulnerabilities, yet play a critical role in maintaining the security of OS kernels. Their wide attack surface, exposed via both the system call interface and the peripheral interface, is often found to be the most direct attack vector to compromise an OS kernel. Researchers therefore have proposed many fuzzing techniques to find vulnerabilities in kernel drivers. However, the performance of kernel fuzzers is still lacking, for reasons such as prolonged execution of kernel code, interference between test inputs, and kernel crashes
The main claimed contributions of this study are:
- propose a new primitive in kernel driver fuzzing. They introduce dynamic virtual machine checkpointing to accelerate kernel driver fuzzing;
- propose checkpoint management policies that can increase the utility of checkpoints created during the dynamic checkpointing process.
Background
Fuzzing is the process of running an automated test of a program by passing input to a target, checking for unexpected behavior, and then starting over again with subtly different input. The goal of fuzzing is to comprehensively test as much of the code as possible with potential input that is likely to occur as well as input that is most likely to cause unexpected behavior.
Modern fuzzing utilizes coverage tracing to detect how far in the program code progress was made, and to detect if subsequent input makes further progress into the code. This allows dynamic adaptation and mutation of input to continue making further and further progress into the code. This can be detected and logged as the total number of execution pathways into the code.
Userspace fuzzing such as AFL tests code running in the operating system’s user space sandbox, which protects the system from system crashes and makes error detection relatively easy and painless. Input, usually, is a sequence of bytes.
Agamotto fuzzes in the kernel space, which has significantly more technical obstacles. Virtual devices cannot be used, as you need to test the hardware directly. Successfully detecting bugs usually crashes the machine. This could lead to the loss of test data and the necessity of resetting or restoring the machine, which significantly slows the testing process. As a result, You cannot simply fork off new processes or use copy-on-write to minimize overhead. In addition, instead of the input being a sequence of bits, a kernel fuzzer sends a sequence of actions or system calls, which have a rigid format that is not not effectively explored using mutational fuzzing methods.
Motivation: How do you fuzz the kernel?
Motivation: How do you fuzz the kernel?
Google came up with their own proprietary methods, but we only have implementation details of open source methods. The simplest approach would be to send a sequence of syscalls and vary their arguments. Since you use random input and not sequential input, you generate different seeds for random number sequences. This allows you to either replay particular tests again in the future, or pick different seeds for every trial to improve the chance of generating unexpected behavior or a software crash.
Kernel fuzzing tests long sequences of actions that change the system state. Imagine you have a base test case with 10,000,000 syscalls. While executing the syscalls the machine changes the contents of memory, accepts input, and writes output. Now, for testing, the fuzzer is focusing on the last syscall. Thus, it would make more sense to set a checkpoint to the system state at syscall 9,999,999 and only execute the instructions that are changing from one test to another.
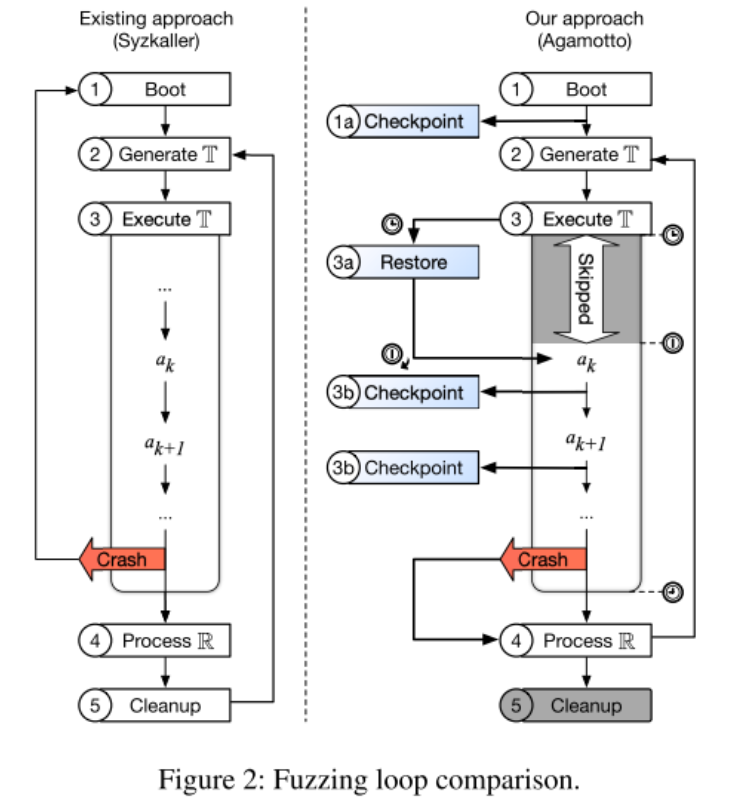
The purpose of these checkpoints is to create a noticeable speed up in kernel mode fuzzing operation. In theory, this looks very simple to perform, but in practice a number of complications and additional implementation details need to be considered.
Checkpoint Storage Data Structure
Each checkpoint must represent a complete snapshot of the virtual machine at a particular point in time. This consists of 1) CPU state data 2) memory contents and 3) VM metadata. In terms of size, the complete contents of RAM are huge. As a result, each checkpoint that contains a complete snapshot of memory creates a burden in both the amount of storage necessary to save the snapshot and in the amount of time it takes to restore the system.
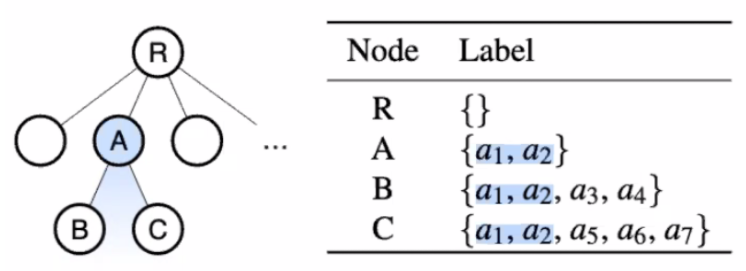
An optimization to minimize this is to store only one initial static checkpoint with the complete contents of memory, and any additional checkpoints will only store the delta encoding differences between the contents of memory of that static checkpoint and any subsequent checkpoints.
 )
)
The data structure used to store these checkpoints is a prefix tree or ‘trie’. The node that represents your checkpoint is represented by the branch of actions necessary to get to that particular node. This allows us to find the best possible checkpoint in effectively linear time, as we traverse down the tree as far as possible to find the checkpoint that matches as much of the prefix of actions as possible. This represents the checkpoint that allows us to skip the largest amount of work possible for that particular input.
Effective Checkpoint Policies
Creating too few checkpoints limits the cache hit rate. Creating too many checkpoints wastes storage capacity and creates excessive checkpointing overhead, which will slow down the system as well. This makes it necessary to develop policies that will minimize the number of checkpoints created and effectively remove unused checkpoints from the cache.
Creation Policies:
- Favoring checkpoints near the start of execution
- Increasing interval of checkpoints, according to the depth of the checkpoint tree
- Don’t checkpoint mutations until they lead to further code coverage
Eviction Policies:
Scoring the value of the pathway as “interesting enough” or significant. This means simply that the current active node and all of its parents are excluded from eviction
Keeping nodes closer to the root with potentially more branches than leaves. This is implemented by simply excluding all nodes that contain child nodes and only examining leaf nodes
Favoring checkpoints that have been used more recently. Looking at all of the candidates not excluded by the previous 2 steps, the checkpoint that has been least recently used is evicted.
Efficient Checkpoint Restoration
Since the current system state is most likely more similar to the checkpoint than the original static checkpoint being stored, it is more efficient to restore the checkpoint by examining the difference between the current system state and the target state we want to restore, rather than go back to the original stored memory checkpoint.
This is performed in practice by traversing the tree from the current to the target state, and obtaining the most recent common ancestor. We then can take the union of all of the pages modified by our current state up to the common ancestor stage, which need to be restored, and then the pages from the common ancestor state down to the target state which need to be applied. This provides us with an optimized minimum number of actual pages that need to be changed.
Implementation
Agamotto uses system calls to implement kernel fuzzing, by using the same framework as syzkaller. They use a high-level description language to describe exactly what to implement: for example, file type, return type, and exactly what syscalls you are willing to use in this particular instance.
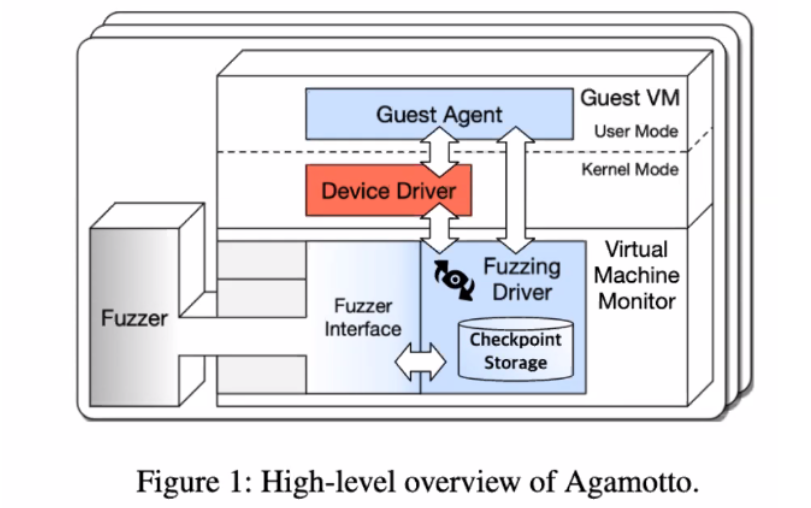
The fuzzer is implemented outside of the virtual machine and interacts with the VM using a low-kernel interface where they interact through shared memory and use hypercalls. They also use a fuzzing driver as seen here which interacts directly with the device drivers and guest agents within the virtual machine.
Agamotto has support for 3 different packages: qemu, hostvm, syzkaller. Qemu implements snapshotting, however, the snapshot implementation has been modified as previously discussed. Instead of implementing change-on-redirect, the authors have implemented change-on-write. Patches applied to syzkaller allow them to determine how often a checkpoint has been accessed and change the snapshot implementation as well. All of these requests are issued through hypercalls.
Working code for this can be found on Secure System Lab’s Github
Evaluation
Driver Fuzzing:
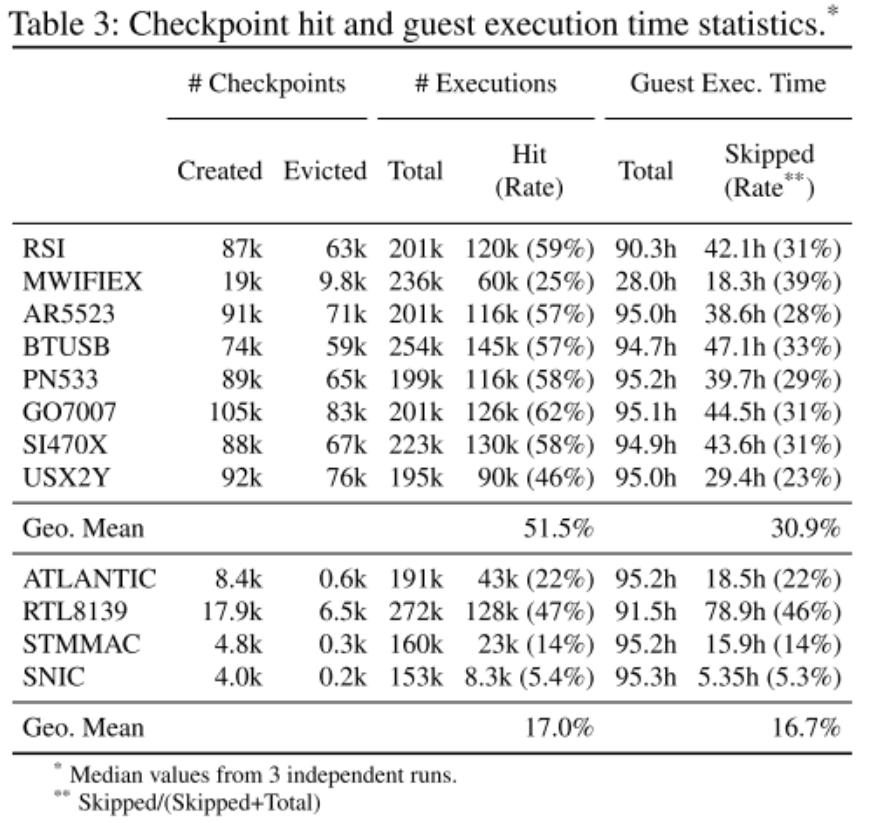
To test the effectiveness of Agamotto in speeding up the operation of Syzkaller, 8 USB drivers from 8 different vendors were fuzzed. 32 independent instances were used for each target, each started with a unique seed to make sure that there was no duplication of work, and each driver was fuzzed for a total of 3 hours. Each experiment was performed 3 times and the results were averaged.
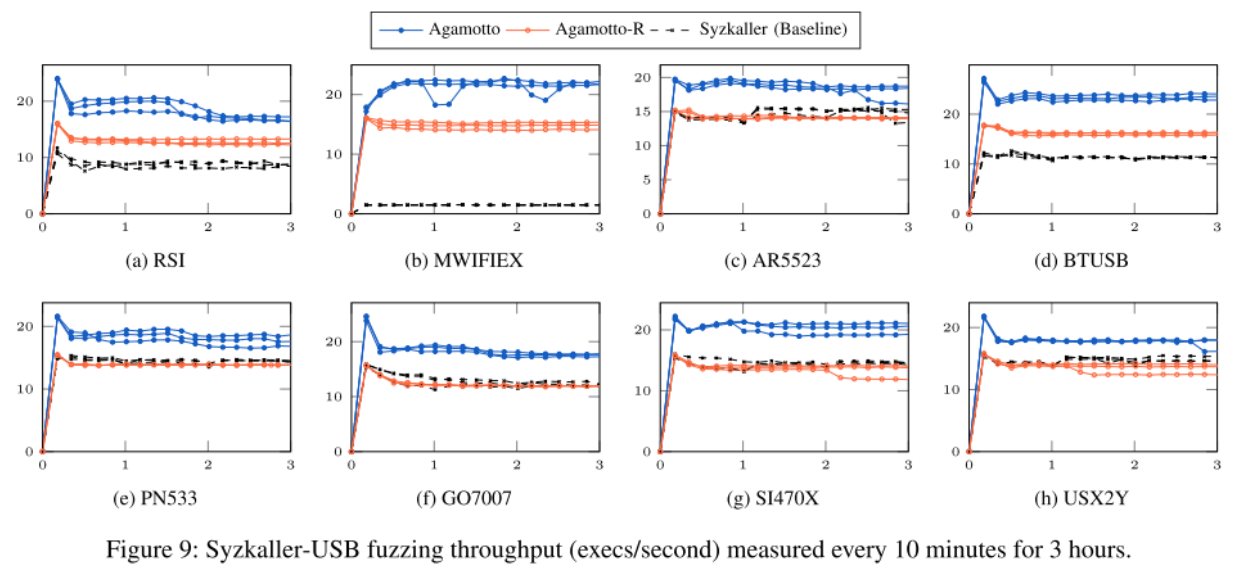
Benchmarking was performed for 3 different configurations: the first using unmodified Syzkaller, Agamotto-Root, a version of Agamotto with all of its enhancements that always restored to the root node, and the full version of Agamotto with its dynamic caching and restoring implementations. The checkpoint caching hit rate barely reached about 50%.
In all cases, Agamotto-Root performed equivalent or better than base Syzkaller, and Agamotto performed the same or better than Agamotto-Root.
As was the case in the USB experiments, there is a spike at the very beginning of execution. However, most instances experienced an increase in executions the longer the fuzzer was run.
This is due to the fact that when a fuzzer first begins, it is more likely to discover more execution pathways. The fuzzing algorithm used mutates the initial seed 100 times. These small mutations on the same seed allow the checkpoints to significantly decrease runtime.

Figure 12 shows a comparison between restored and dirtied pages as a function of frequency and amount. Large groups of pages are frequently restored, however, large groups of dirtied pages are less frequently encountered. The deeper into the execution the fuzzer gets, the less information that is cached and as a result, pages are restored more often instead of creating another checkpoint.
PCI Fuzzing:
Much like the USB driver fuzzing, the pci fuzzing was run on 32 independent instances where each instance was fuzzed for a total of 3 hours and the results are an average of 3 experiments.
Conclusion
Agamotto is a fuzzer backend that decreases the run-time of a fuzzing iteration through the clever use of checkpoints to restore dirtied memory pages at the end of a run. The input-based checkpoints rather than basic-block based checkpoints essentially maps a state to an input which hasn’t been easily achieved before in the field of fuzzing. The limited 3-hour tests shows promise but feels too limited of a trial to give a sense of the potential for this concept.
As seen in the benchmarks, rarely was there more than a 2X factor in speed up. This could be because as the authors stressed, the fuzzing algorithm was not modified in any way. Conceivably additional work in this area could be done to optimize the input chosen by the fuzzer to optimize the caching hit rate of the dynamically generated checkpoints, and yet not distort the optimum generation of these checkpoints (maybe with multiple passes). With far higher checkpoint hit rates, rather than the 20%-60% seen in these trials, more significant speedup might be achieved.
Another benefit that was not well developed was Agamotto’s greater resilience to kernel panics. Since Agamotto puts the fuzzer outside of the virtual machine, it was able to bypass an existing “shallow bug” in one USB driver and find an unknown bug that was never found by competing products. This benefit might be significant when evaluating relatively buggy software. Rather than evaluating Agamotto simply by its performance, another approach could be done to benchmark this improvement. It seems feasible that another series of trials could determine just how much more effective Agamotto is compared to competing products in achieving greater code coverage and greater number of bugs discovered.